Процесс — экземпляр программы во время выполнения, независимый объект, которому выделены системные ресурсы (например,
процессорное время и память). Каждый процесс выполняется в отдельном адресном пространстве: один процесс не может
получить доступ к переменным и структурам данных другого. Если процесс хочет получить доступ к чужим ресурсам,
необходимо использовать межпроцессное взаимодействие. Это могут быть конвейеры, файлы, каналы связи между компьютерами и
многое другое.
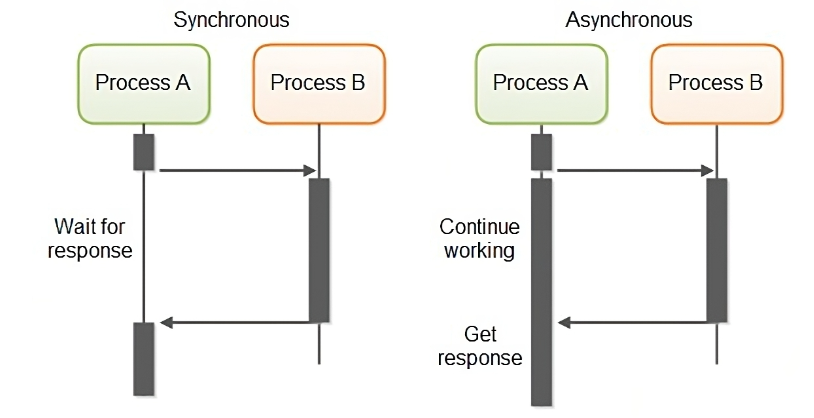
Синхронным (synchronous) называется такое взаимодействие между компонентами, при котором клиент, отослав запрос,
блокируется и может продолжать работу только после получения ответа от сервера. По этой причине такой вид взаимодействия
называют иногда блокирующим (blocking).
В рамках асинхронного (asynchronous) или неблокирующего (non blocking) взаимодействия клиент после отправки запроса
серверу может продолжать работу, даже если ответ на запрос еще не пришел. Асинхронное взаимодействие позволяет получить
более высокую производительность системы за счет использования времени между отправкой запроса и получением ответа на
него для выполнения других задач. Другое важное преимущество асинхронного взаимодействия — меньшая зависимость клиента
от сервера, возможность продолжать работу, даже если машина, на которой находится сервер, стала недоступной. Это
свойство используется для организации надежной связи между компонентами, даже если и клиент, и сервер не все время
находятся в рабочем состоянии.
NoSQL (от англ. Not Only SQL — не только SQL) — термин, обозначающий ряд подходов, направленных на реализацию систем
управления базами данных, имеющих существенные отличия от моделей, используемых в традиционных реляционных СУБД с
доступом к данным средствами языка SQL. Применяется к базам данных, в которых делается попытка решить проблемы
масштабируемости и доступности за счёт атомарности (англ. atomicity) и согласованности данных (англ. consistency).
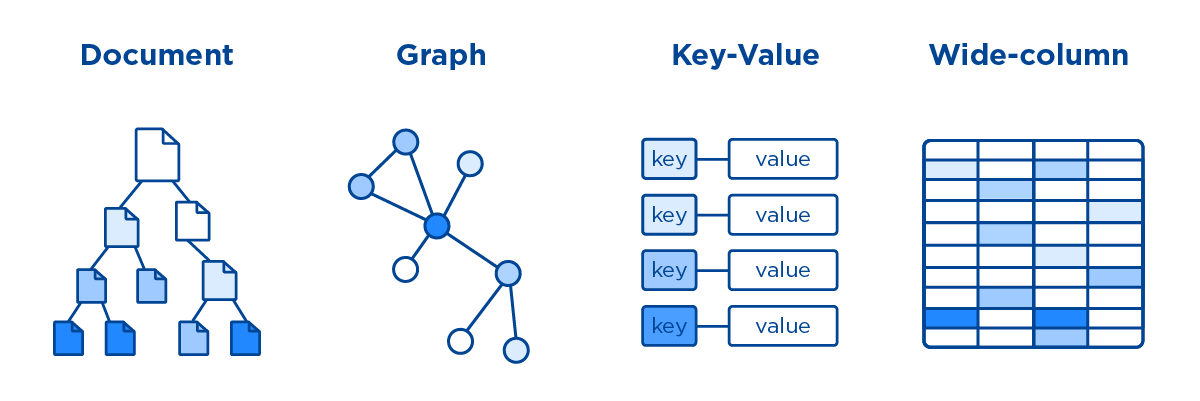
Все NoSQL решения принято делить на 4 типа:
-
Ключ-значение (Key-value)– наиболее простой вариант хранилища данных, использующий ключ для доступа к значению в рамках большой хэш-таблицы. Такие СУБД применяются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в масштабируемых Big Data системах, включая игровые и рекламные приложения, а также проекты интернета вещей (Internet of Things, IoT), в т.ч. индустриального (Industrial IoT, IIoT). Наиболее известными представителями нереляционных СУБД типа key-value считаются Oracle NoSQL Database, Berkeley DB, MemcacheDB, Redis, Riak, Amazon DynamoDB, которые поддерживают высокую разделяемость, обеспечивая беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД. -
Документо-ориентированное хранилище, в котором данные, представленные парами ключ-значение, сжимаются в виде полуструктурированного документа из тегированных элементов подобно JSON, XML, BSON и другим подобным форматам. Такая модель хорошо подходит для каталогов, пользовательских профилей и систем управления контентом, где каждый документ уникален и изменяется со временем. Поэтому чаще всего документные NoSQL-СУБД используются в CMS-системах, издательском деле и документальном поиске. Самые яркие примеры документно-ориентированных нереляционных баз данных – это CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML. -
Колоночное хранилище, которое хранит информацию в виде разреженной матрицы, строки и столбцы которой используются как ключи. В мире Big Data к колоночным хранилищам относятся базы типа «семейство столбцов» (Column Family). В таких системах сами значения хранятся в столбцах (колонках), представленных в отдельных файлах. Благодаря такой модели данных можно хранить большое количество атрибутов в сжатом виде, что ускоряет выполнение запросов к базе, особенно операции поиска и агрегации данных. Наличие временных меток (timestamp) позволяет использовать такие СУБД для организации счётчиков, регистрации и обработки событий, связанных со временем: системы биржевой аналитики, IoT/IIoT-приложения, систему управления содержимым и т.д. Самой известной колоночной базой данных является Google Big Table, а также основанные на ней Apache HBase и Cassandra. Также к этому типу относятся менее популярные ScyllaDB, Apache Accumulo и Hypertable. -
Графовое хранилищепредставляют собой сетевую базу, которая использует узлы и рёбра для отображения и хранения данных. Поскольку рёбра графа являются хранимыми, его обход не требует дополнительных вычислений (как соединение в SQL). При этом для нахождения начальной вершины обхода необходимы индексы. Обычно графовые СУБД поддерживают ACID-требования и специализированные языки запросов (Gremlin, Cypher, SPARQL, GraphQL и т.д.). Такие СУБД используются в задачах, ориентированных на связи: социальные сети, выявление мошенничества, маршруты общественного транспорта, дорожные карты, сетевые топологии. Примеры графовых баз: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB.
У SQL и NoSQL баз данных свои преимущества и недостатки, и необходимо понимать, когда и что использовать.
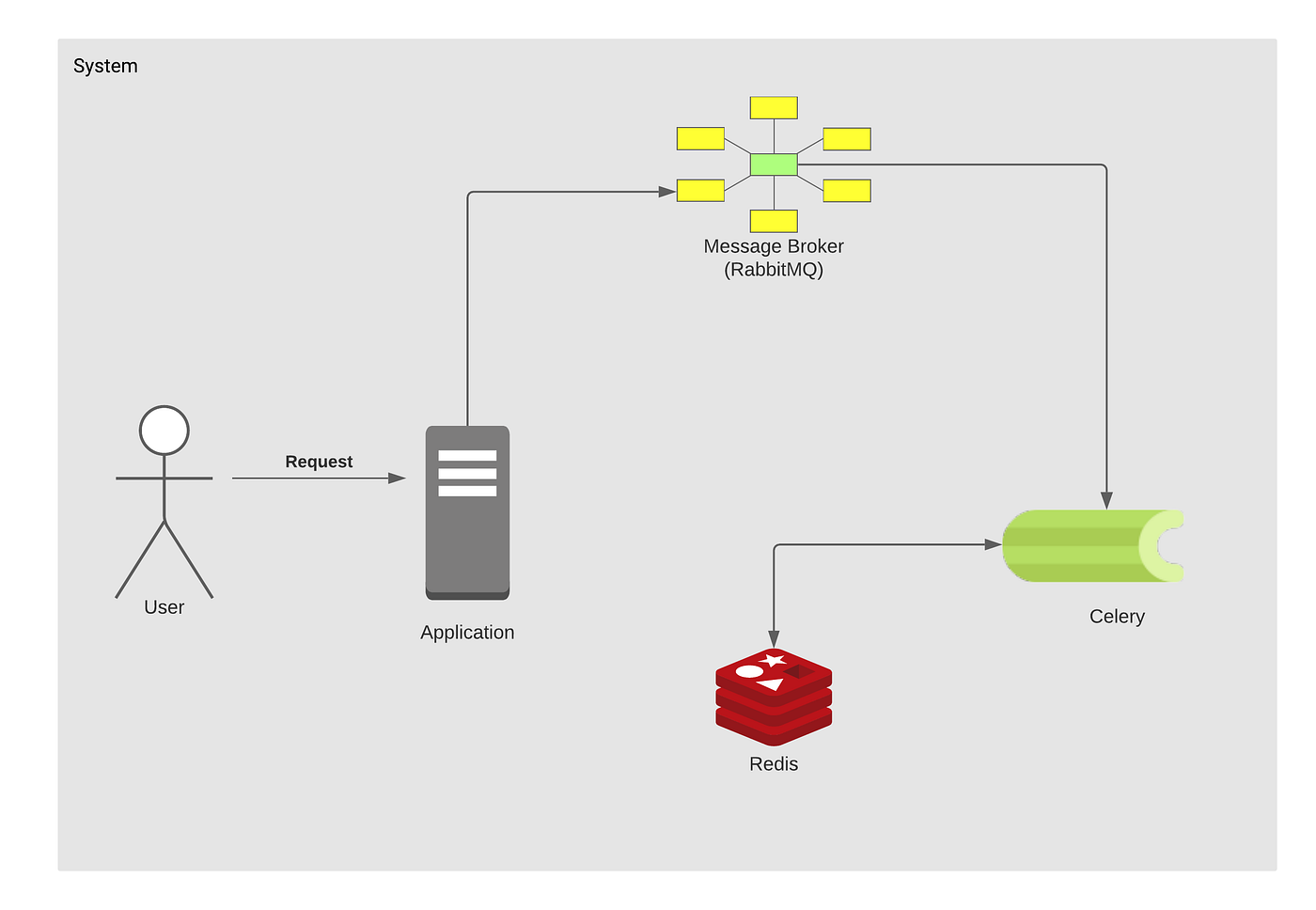
Celery – это система для управления очередями задач. Принципиально умеет 2 вещи: брать задачи из очереди и выполнять задачи по расписанию.
Celery - это распределённая очередь задач, реализованная на языке Python.
Celery - это простая, гибкая и надежная распределенная система для обработки огромного количества сообщений, включая в себя инструменты, необходимые для поддержки такой системы.
Это очередь задач с упором на обработку в реальном времени, а также с поддержкой планирования задач.
Celery имеет открытый исходный код и находится под лицензией BSD.
Итак, что же умеет Celery:
- Выполнять асинхронно задания
- Выполнять периодические задания (умная замена cron)
- Выполнять отложенные задания
- Распределенное выполнение (может быть запущен на N серверах)
- В пределах одного worker’а возможно конкурентное выполнение нескольких задач (одновременно)
- Выполнять задание повторно, если вылез exception
- Ограничивать количество заданий в единицу времени (rate limit для задания или глобально)
- Несложно мониторить выполнение заданий
- Выполнять подзадания
- Присылать отчеты об exception’ах
- Проверять выполнилось ли задание
Задачей является предварительно написанный код (чаще всего функция), предназначенный для выполнения определённой цели (отправка имейла, обработка файла, и т. д.)
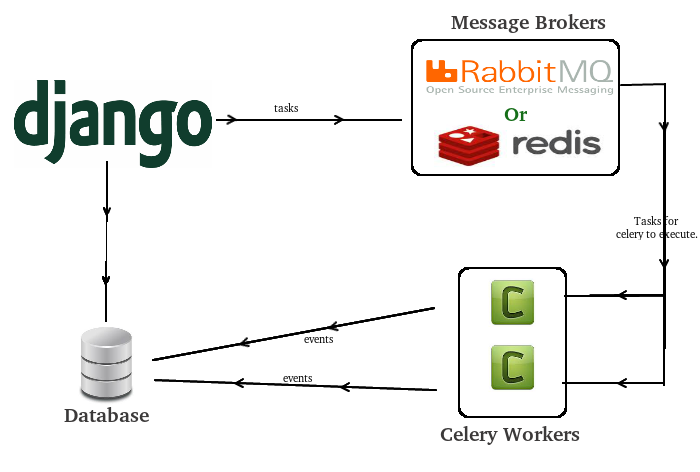
Брокер сообщений (он же диспетчер очереди) — это посредник(транспорт), который принимает и отдает сообщения (задачи) между отдельными модулями/приложениями внутри некоторой сложной системы, где модули/приложения должны общаться между собой — то есть пересылать данные друг другу.
Брокером может выступать как специальное ПО, например, RabbitMQ, так и некоторые NoSQL, например Redis. О них подробнее ниже.
Воркер - это отдельно запущенный процесс для выполнения определённых задач, Celery запускается на одном или нескольких воркерах, чтобы выполнять задачи параллельно на каждом воркере.
В рамках Celery бэкэнд выступает в качестве хранилища результатов выполнения задач. Это может быть как SQL, так и NoSQL база данных. Хотя, по сути что угодно может быть хранилищем, хоть обычный файл (я таких реализаций не встречал, но технически возможно).
-
Producer (поставщик) ‒ программа, отправляющая сообщения. В нашем случае, это чаще всего будет Django.
-
Queue (очередь) ‒ очередь сообщений (задач). Она существует внутри брокера. Любое количество поставщиков может отправлять сообщения в одну очередь, также любое количество подписчиков может получать сообщения из одной очереди. В схемах очередь будет обозначена стеком и подписана именем. Чаще всего за очередь будет отвечать Redis.
-
Consumer (подписчик) ‒ программа, принимающая сообщения. Обычно подписчик находится в состоянии ожидания сообщений. Это будет процесс Celery, который запустили специально для этой цели. Обрабатывает задачи, и складывает результат в backend.
Поставщик, подписчик и брокер не обязаны находиться на одной физической машине.
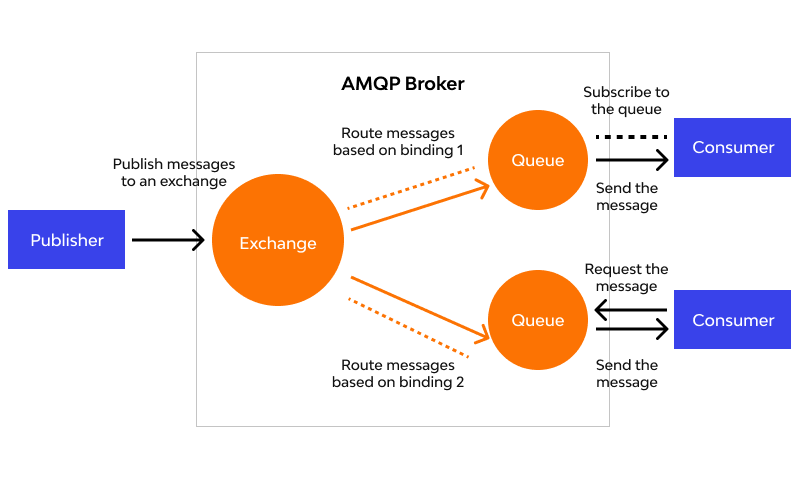
AMQP (Advanced Message Queuing Protocol) — открытый протокол для передачи сообщений между компонентами системы. Основная идея состоит в том, что отдельные подсистемы (или независимые приложения) могут обмениваться произвольным образом сообщениями через AMQP-брокер, который осуществляет маршрутизацию, возможно гарантирует доставку, распределение потоков данных, подписку на нужные типы сообщений.
RabbitMQ – это брокер сообщений с открытым исходным кодом. Он маршрутизирует сообщения по всем базовым принципам
протокола AMQP, описанным в спецификации. Отправитель передает сообщение брокеру, а тот доставляет его получателю.
RabbitMQ реализует и дополняет протокол AMPQ.
Redis (Remote Dictionary Server) – это быстрое хранилище данных типа «ключ‑значение» в памяти с
открытым исходным кодом для использования в качестве базы данных, кэша, брокера сообщений или очереди.
Redis это NoSQL база данных! Для Celery крайне рекомендую использовать именно его.
Для установки celery мы можем использовать pip:
pip install celery
Celery 4.0+ официально уже не поддерживается для Windows
Варианты запуска
-
Использовать Linux
-
WSL 2 (для Windows 10)
Установка самого сервиса
sudo apt install redis-server
Для линукса, или Windows
Для работы также необходима и библиотека
pip install redis
Все три процесса должны быть запущены одновременно! И Python, который будет отправлять сообщения, и Redis, который будет очередью, и Celery worker, который будет выполнять задачи
Если вы используете Windows то для того, чтобы все следующие примеры работали, необходимо использовать только
конкретные версии пакетов и версию Python 3.6!
python == 3.6
celery == 3.1.25
redis == 2.10.6
Создадим файл tasks.py
Для использования необходимо создать "приложение", в котором необходимо указать название и брокера.
from celery import Celery
broker_url = 'redis://localhost'
app = Celery('tasks', broker=broker_url)
@app.task # декорирование функции для использования её через Celery
def add(x, y):
return x + yМы не вызывали задачу!!
Для того чтобы мы могли вызвать задачу, необходимо, чтобы у вас были запущены два отдельных приложения, первое Redis Server:
Запускаем и оставляем работать!
Celery запускать нужно при запущенном виртуальном окружении!
celery -A tasks worker --loglevel=INFO
Также запускаем и не закрываем!
-A app_name - имя приложения, worker - запустить воркер, loglevel - уровень деталей отображаемой информации.
Для запуска задач есть много разных способов, тут рассмотрим базовый.
Открываем консоль:
from tasks import add
add.delay(4, 4)Для запуска задачи немедленно используется метод delay.
Запуск задач возвращает не результат, а AsyncResult, для того чтобы получать значения, необходимо при создании
приложения указать параметр backend, который отвечает за то, где будут храниться результаты, таким параметром может
быть Redis:
broker_url = 'redis://localhost'
app = Celery('tasks', broker=broker_url, backend=broker_url)Обратите внимание, мы используем Redis и в качестве брокера, и в качестве бэкэнда сразу.
Результат будет иметь достаточно большое кол-во методов и атрибутов.
Основные два метода это ready() и get():
ready() - булево поле, которое отвечает за то, завершилась задача или еще в процессе.
get() - ждет выполнения задачи и возвращает результат. Рекомендуется использовать после ready(), чтобы не ждать
выполнения впустую.
result = add.delay(4, 4)
result.ready()
True
result.get()
8Иногда описание параметров задачи и ее вызов могут быть в совершенно разных местах, для этого существует механизм подписи:
s1 = add.s(2, 2)
res = s1.delay()
res.get()В этом примере s1 - это подпись задачи, то есть задача, заготовленная для выполнения, её можно сериализовать и
отправить по сети, например, а выполнить в уже совершенно других местах.
Или если вы не знаете параметры целиком:
# incomplete partial: add(?, 2)
s2 = add.s(2)
# resolves the partial: add(8, 2)
res = s2.delay(8)
res.get()Задачи можно группировать:
from celery import group
from proj.tasks import add
group(add.s(i, i) for i in range(10))().get()Есть три варианта запуска задач:
apply_async(args[, kwargs[, …]])
Отправка сообщения с указанием дополнительных параметров:
delay(*args, **kwargs)
Отправка сообщения без каких-либо параметров самого сообщения:
calling (__call__)
Просто вызов, декоратор не мешает нам просто вызвать функцию без Celery. :)
сountdown- выполнить через определённый промежуток времени
add.apply_async((2, 2), countdown=10)
# выполнить через 10 секундeta- выполнить в конкретное время
add.apply_async((2, 2), eta=now() + timedelta(seconds=10))
# выполнить через 10 секундexpires- время, после которого перестать выполнять задачу, можно указать как цифру, так и время
add.apply_async((4, 5), countdown=60, expires=120)
add.apply_async((4, 5), expires=now() + timedelta(days=2))link- выполнить другую задачу по завершению текущей, основываясь на результатах текущей
add.apply_async((2, 2), link=add.s(16))
# ( 2 + 2 ) + 16Celery может выполнять какие-либо задачи просто по графику.
Для этого нужно настроить приложение:
app.conf.beat_schedule = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': 30.0,
'args': (16, 16)
},
}
app.conf.timezone = 'UTC'Ключ словаря - это только название, можно указать что угодно.
Таск - это выполняемый таск. :)
args - его аргументы.
schedule - частота выполнения в секундах.
from celery.schedules import crontab
app.conf.beat_schedule = {
# Executes every Monday morning at 7:30 a.m.
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (16, 16),
},
}Cron - система задания расписания, можно сделать практически какое угодно.
from celery.schedules import solar
app.conf.beat_schedule = {
# Executes at sunset in Melbourne
'add-at-melbourne-sunset': {
'task': 'tasks.add',
'schedule': solar('sunset', -37.81753, 144.96715),
'args': (16, 16),
},
}В данном случае выполнять во время заката по указанным координатам, параметров много, например, закат с учётом зданий ;)
Для запуска по расписанию нужно запускать отдельный воркер для расписания (смотреть в доке)
Для использования Celery в Django рекомендуется создать еще один файл celery.py на одном уровне с settings.py
from __future__ import absolute_import
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'djangoProject1.settings')
from django.conf import settings # noqa
app = Celery('djangoProject1')
# Using a string here means the worker will not have to
# pickle the object when using Windows.
app.config_from_object('django.conf:settings')
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)app.autodiscover_tasks(lambda: settings.INSTALLED_APPS) - эта строчка будет отвечать за автоматический поиск таков во
всех приложениях.
На том же уровне, где и settings.py создать\использовать файл __init__.py в зависимости от версии Python.
# __init__.py
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ('celery_app',)Все задачи необходимо покрывать не стандартным декоратором task, а декоратором shared_task, тогда Django сможет
автоматически найти все таски в приложении.
# tasks.py
from celery import shared_task
from demoapp.models import Widget
@shared_task
def add(x, y):
return x + y
@shared_task
def mul(x, y):
return x * y
@shared_task
def xsum(numbers):
return sum(numbers)
@shared_task
def count_widgets():
return Widget.objects.count()
@shared_task
def rename_widget(widget_id, name):
w = Widget.objects.get(id=widget_id)
w.name = name
w.save()Также для Django существует много различных расширений, например:
django-celery-results - чтобы хранить результаты в БД или кеше Django, за подробностями в доку.
django-celery-beat - настройка для периодических задач, сразу вшитая в админку Django, за подробностями опять же в
доку.
Практика/Домашка:
-
Настроить у себя Celery, чтобы запускались хоть какие-то таски.
-
Сделать кнопку для админа, которая будет подтверждать все возвраты через Celery task.
-
Создать таск, который будет отклонять все возвраты в 6 часов вечера по Киеву.