Ledger 的元数据信息保存在zookeeper中。

当写入发生时,首先 entry 被写入一个 journal 文件。journal 是一个 write-ahead log(WAL),它帮助 BookKeeper 在发生故障时避免数据丢失。这与关系型数据库实现数据持久化的机制相同。
同时 entry 会被加入到 write cache 中。write cache 中累积的 entry 会定期排序,异步刷盘到 entry log 文件中。同一个 ledger 的 entry 排序后会被放在一起,这样有利于提高读取的性能。
write cache 中的 entry 也将被写入 RocksDB, RocksDB 记录了每个 entry 在 entry log 文件中的位置,是 (ledgerId, entryId) 到 (entry log file, offset) 的映射,即可以通过(ledgerId, entryId),在 entry log 文件中定位到 entry。
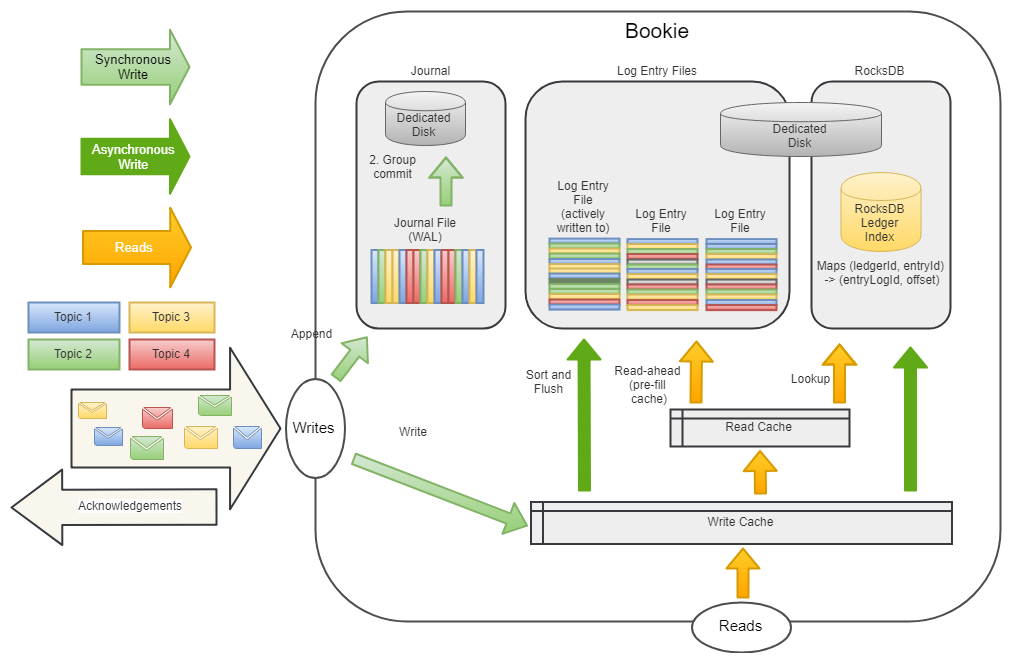
读取时会首先查看 write cache ,因为 write cache 中有最新的 entry。如果 write cache 中没有,那么接着查看 read cache。如果 read cache 中还是没有,那么就通过 (ledgerId, entryId) 在 RocksDB 中查找到该 entry 所在的 entry log 文件及偏移量,然后从 entry log 文件中读取该 entry ,并更新到 read cache 中,以便后续请求能在 read cache 中命中。两层缓存让绝大多数的读取通常是从内存获取。
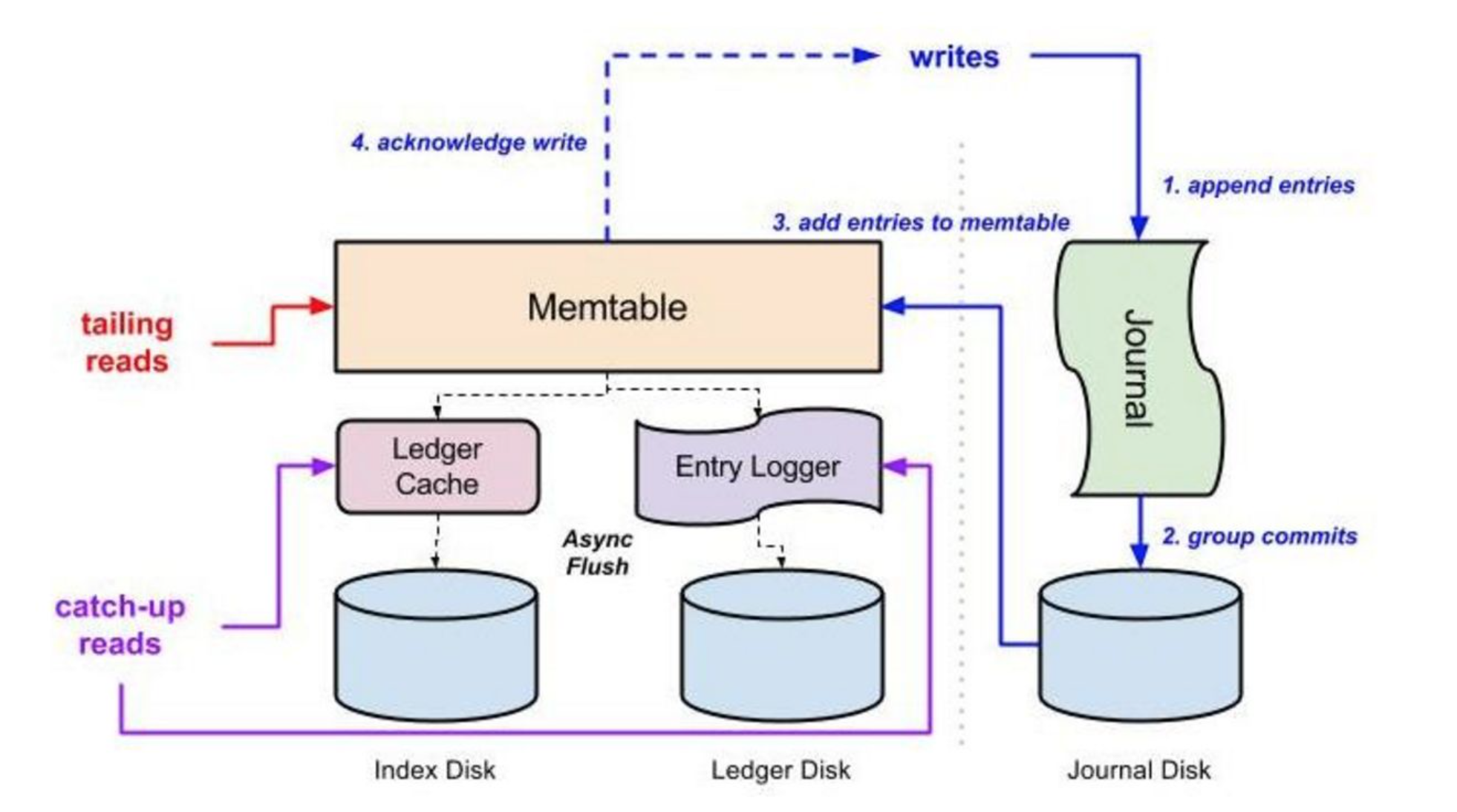
journal 文件,该文件可以存储在专用磁盘上,可以获得更大的吞吐量。write cache 中的 entry 会异步批量写入 entry log 文件和 RocksDB,通常配置在另外一块磁盘。因此,一个磁盘用于同步写入( journal 文件),另一个磁盘用于异步优化写入,以及所有的读取。
Bookie 操作基本都是在客户端完成和实现的,比如副本复制、读写 entry 等操作。这些有助于确保 BookKeeper 的一致性。
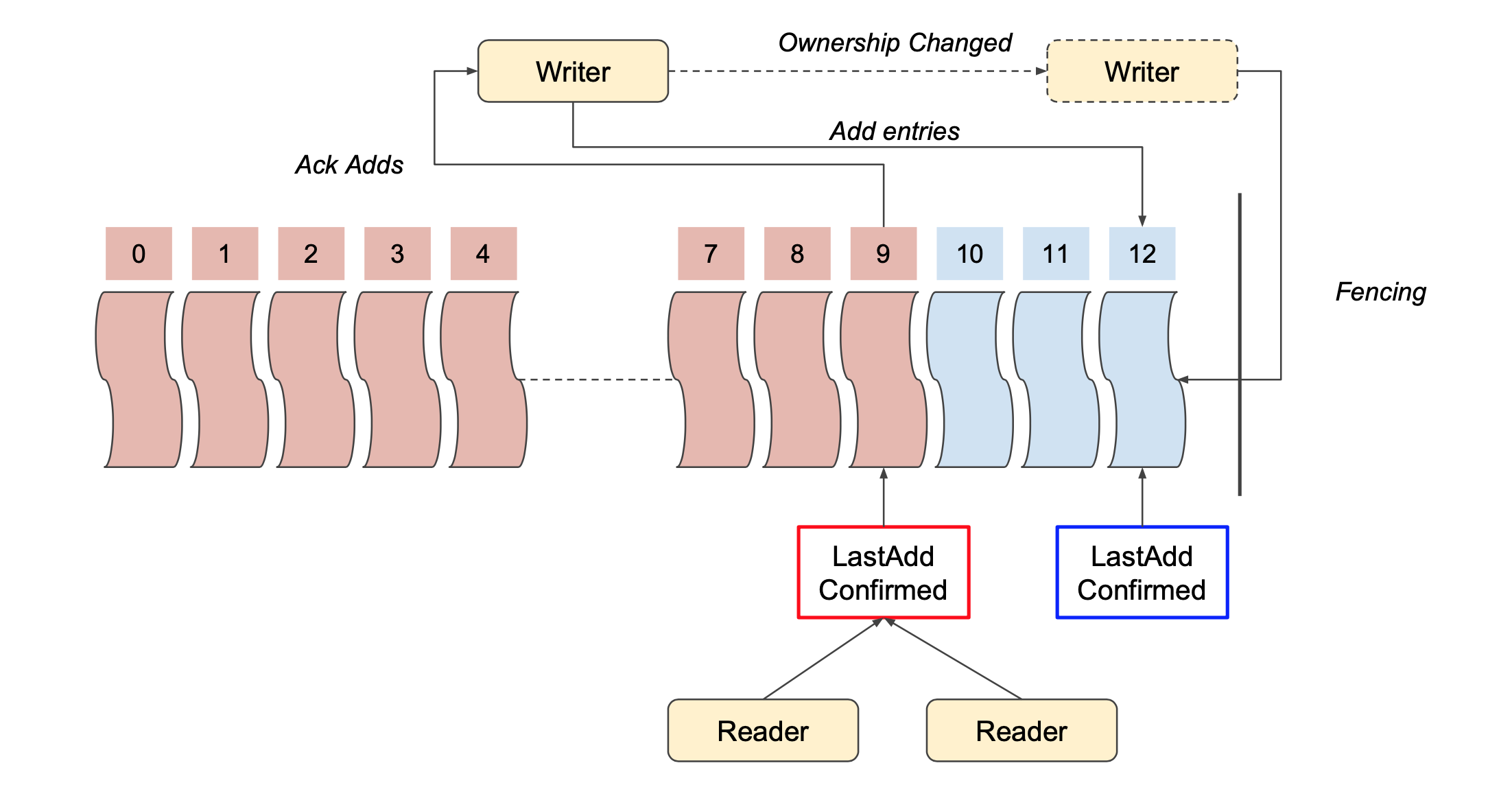
客户端在创建 ledger 时,会出现 Ensemble、Write Quorum 和 Ack Quorum 这些数据指标。
-
Ensemble —— 用哪几台 bookie 去存储 ledger 对应的 entry
-
Write Quorum ——对于一条 entry,需要存多少副本
-
Ack Quorum —— 在写 entry 时,要等几个 response
我们会用(5,3,2)的实例进行讲述

虽然总体是需要 5 台 bookie,但是每条 entry 只会占用 3 台 bookie 去存放,并只需等待其中的 2 台 bookie 给出应答即可。
LAC(LastAddConfirm)是由 LAP(LastAddPush) 延伸而来是根据客户端进行维护并发布的最后一条 entry id,从 0 开始递增。所以 LAC 是由应答确认回来的最后一条 entry id 构成,如下图右侧显示。 
当其中的某个 bookie 挂掉时,客户端会进行一个 ensemble change 的操作,用新的 bookie 替换挂掉的旧 bookie。比如 当bookie 4 挂掉时,可以使用 bookie 6 进行替换。 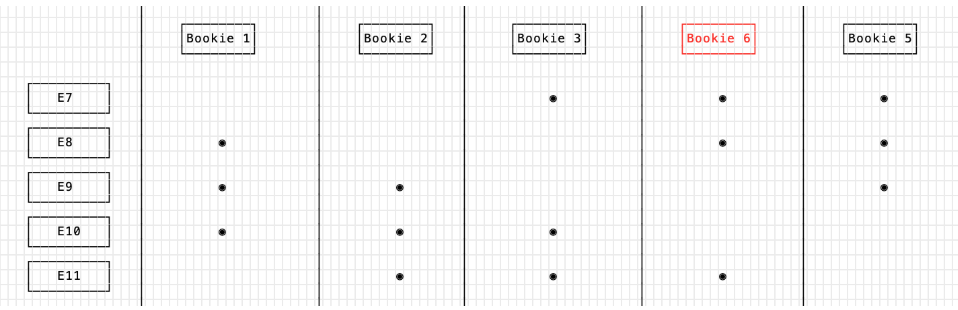
Ensemble change 对应到元数据存储,即对元数据的修改。之前的 E0-E6 是写在 B1~B5 上,E7 以后写在了 B1、B2、B3、B6、B5 上。这样就可以通过元数据的方式,看到数据到底存储在那个bookie上。

BookKeeper 有一个极其重要的功能,叫做 fencing。fencing 功能让 BookKeeper 保证只有一个写入者(Pulsar broker)可以写入一个 ledger。
Broker(B1)挂掉,Broker(B2)接管 B1 上topic X的流程:
-
当前拥有 topic X 所有权的Pulsar Broker(B1)被认为已经挂掉或不可用(通过ZooKeeper)。
-
另一个Broker(B2)将topic X 的当前 ledger 的状态从 OPEN 更新为 IN_RECOVERY。
-
B2 向当前 ledger 的所有 bookie 发送 fencing LAC read 请求,并等待(Write Quorum - Ack Quorum)+1的响应。一旦收到这个数量的回应,ledger 就已经被 fencing。B1就算还活着,也不能再写入这个ledger,因为B1无法得到 Ack Quorum 的确认。
-
B2采取最高的LAC响应,然后开始执行从 LAC+1 的恢复性读取。它确保从该点开始的所有 entry 都被复制到 Write Quorum 个bookie。当 B2 不能再读取和复制任何entry,ledger 完成恢复。
-
B2将 ledger 的状态改为 CLOSED。
-
B2打开一个新的 ledger,现在可以接受对Topic X的写入。
整个失效恢复的过程,是没有回头复用 ledger 的。因为复用意味着所有元素都处于相同状态且都同意后才能继续去读写,这个是很难控制的。
我们从主从复制方式进行切入,将其定义为物理文件。数据从主复制到从,由于复制过程的速度差异,为了保证所有的一致性,需要做一些「删除/清空类」的操作。但是这个过程中一旦包含覆盖的操作,就会在过程中更改文件状态,容易出现 bug。
BookKeeper 在运行的过程中,不是一个物理文件,而是逻辑上的序。同时在失效恢复过程中,没有进行任何的复用,使得数据恢复变得简单又清晰。其次它在整个修复过程中,没有去额外动用 ledger X 的数据。
当一个 bookie 失败时,这个 bookie 上所有 ledger 的 fragments 都将被复制到其他节点,以确保每个 ledger 的复制系数(Write quorum)得到保证。
recovery 不是 BookKeeper 复制协议的一部分,而是在 BookKeeper 外部运行,作为一种异步修复机制使用。
有两种类型的recovery:手动或自动。
自动恢复进程 AutoRecoveryMain 可以在独立的服务器上运行,也可以和bookie跑在一起。其中一个自动恢复进程被选为审核员,然后进行如下操作:
-
从 zookeeper 读取所有的 ledger 列表,并找到位于失败 bookie上的 ledger。
-
对于第一步找到的所有ledger,在ZooKeeper上创建一个复制任务。
AutoRecoveryMain 进程会发现 ZooKeeper 上的复制任务,锁定任务,进行复制,满足Write quorum,最后删除任务。
通过自动恢复,Pulsar集群能够在面对存储层故障时进行自我修复,只需确保部署了适量的bookie就可以了。
如果审计节点失败,那么另一个节点就会被提升为审计员。