This project is dedicated to addressing the issue of detecting deepfake audio by leveraging sophisticated neural network architectures like VGG16, MobileNet, ResNet, and custom CNNs. Employed GANs for audio content synthesis. By integrating explainable AI (XAI) methodologies such as LIME, Grad-CAM, and SHAP, the project aims to not only improve detection accuracy but also offer meaningful insights into the model's predictions.
- Deep Learning Models: VGG16, MobileNet, ResNet, Custom CNNs
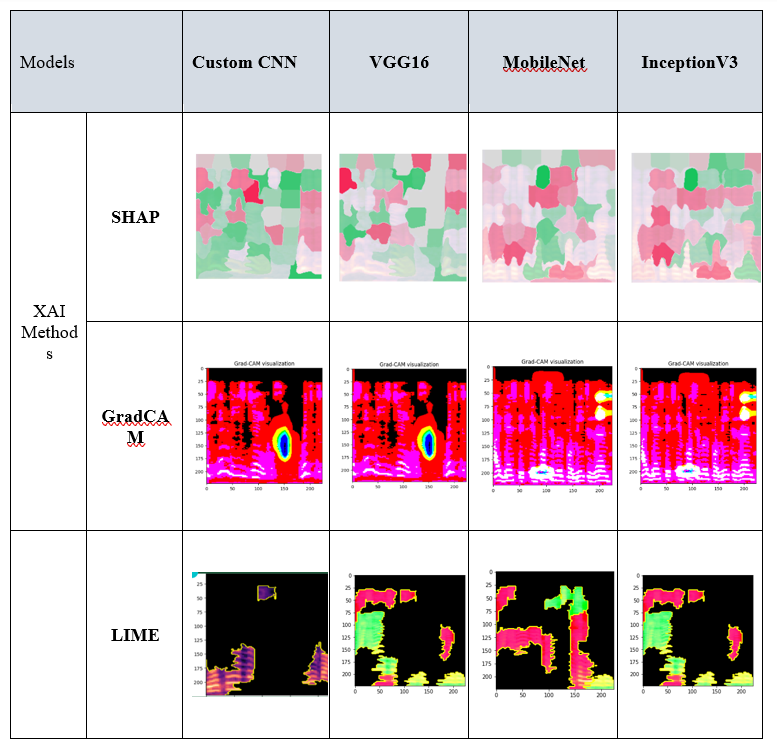
- Explainable AI (XAI) Techniques: LIME, Grad-CAM, SHAP
- Data Processing: Spectrogram conversion for audio data
- Programming Languages and Libraries: Python, TensorFlow, Keras, Matplotlib, NumPy
- Development Tools: Jupyter Notebooks
- Web Application Framework: Streamlit for interactive web app deployment
- Use of various deep learning models for audio classification.
- Conversion of audio to spectrograms for improved model performance.
- Application of XAI methods for greater transparency in model decisions.
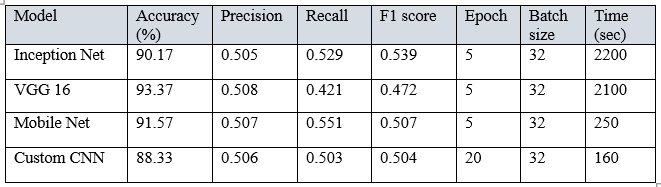
- Comparative analysis of different models based on accuracy and explainability.
The dataset used for training our deepfake audio detection models is the 'Fake or Real' dataset, created by researchers from York University. This dataset consists of authentic and deepfake audio recordings that have been used to train our models to distinguish between real and fake samples effectively.
For enhanced model performance, the audio files were converted into spectrograms. Spectrograms are visual representations of the spectrum of frequencies in a sound or other signal as they vary with time, which provides a more informative feature set for deep learning models.
This project includes a Streamlit web application that provides a user-friendly interface for interacting with the deepfake audio detection models. Below is a preview of the application in action.

- Aamir Hullur
- Atharva Gurav
- Aditi Govindu
- Parth Godse