If our project helps you, please give us a star ⭐ and cite our paper!
- [2024.05.25] 🔥 Our checkpoints are available now!
- [2024.05.23] 🔥 Our paper is released!
Sparse MoE (SMoE) has an unavoidable drawback: the performance of SMoE heavily relies on the choice of hyper-parameters, such as the number of activated experts per token (top-k) and the number of experts.
Also, identifying the optimal hyper-parameter without a sufficient number of ablation studies is challenging. As the size of the models continues to grow, this limitation could result in a significant waste of computational resources, and in turn, could hinder the efficiency of training MoE-based models in practice.
Now, our DynMoE addresses these challenges through the two components introduced in Dynamic Mixture of Experts (DynMoE).

We first introduce a novel gating method that enables each token to automatically determine the number of experts to activate.
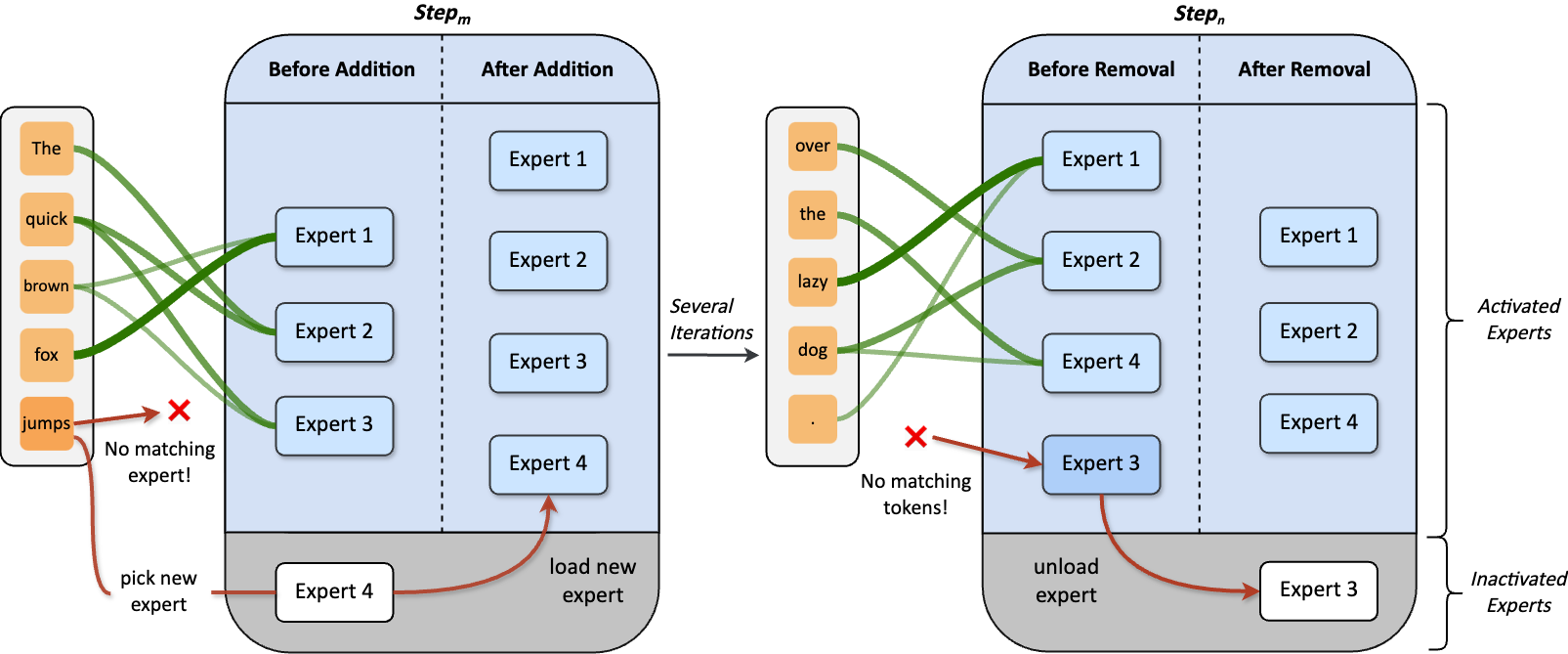
Our method also includes an adaptive process automatically adjusts the number of experts during training.
- On language tasks, DynMoE surpasses the average performance among various MoE settings.
- Effectiveness of DynMoE remains consistent in both Vision and Vision-Language tasks.
- Although sparsity is not enforced in DynMoE, it maintains efficiency by activating even less parameters!
| Model | Activated Params / Total Params | Transformers(HF) |
|---|---|---|
| DynMoE-StableLM-1.6B | 1.8B / 2.9B | LINs-lab/DynMoE-StableLM-1.6B |
| DynMoE-Qwen-1.8B | 2.2B / 3.1B | LINs-lab/DynMoE-Qwen-1.8B |
| DynMoE-Phi-2-2.7B | 3.4B / 5.3B | LINs-lab/DynMoE-Phi-2-2.7B |
EMoE/contains experiments on language and vision tasks, which uses tutel-based DynMoE.MoE-LLaVA/contains experiments on language-vision tasks, which uses deepspeed-0.9.5-based DynMoE.
Deepspeed/provides DynMoE-Deepspeed implementation.EMoE/tutel/provides DynMoE-Tutel implementation.
Please refer to instructions under EMoE/ and MoE-LLaVA.
Please refer to EMoE/Language/README.md and EMoE/Language/Vision.md.
Network Configuration
deepspeed.moe.layer.MoE(
hidden_size=84,
expert=fc3,
num_experts=n_e // 2,
ep_size=args.ep_world_size,
use_residual=args.mlp_type == "residual",
k=-1, # -1 means using DynMoE
min_capacity=args.min_capacity,
noisy_gate_policy=args.noisy_gate_policy,
max_expert_num=n_e
)Training model forward, you can control the adaptive process by using if_begin_record_routing, if_end_record_routing.
outputs = model_engine(inputs, if_begin_record_routing=True, if_end_record_routing=True)We are grateful for the following awesome projects:
If you find this project helpful, please consider citing our work:
@misc{guo2024dynamic,
title={Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models},
author={Yongxin Guo and Zhenglin Cheng and Xiaoying Tang and Tao Lin},
year={2024},
eprint={2405.14297},
archivePrefix={arXiv},
primaryClass={cs.LG}
}