Public meeting articles are the key to understanding the history of public opinion and public sphere in Australia. Information extraction from public meeting articles can obtain new insights into Australian history. In this paper, we create an information extraction dataset in the public meeting domain. We manually annotate the date and time, place, purpose, people who requested the meeting, people who convened the meeting, and people who were convened of 1,258 public meeting articles. We further present an information extraction system, which formulates information extraction from public meeting articles as a machine reading comprehension task. Experiments indicate that our system can achieve an F1 score of 74.98% for information extraction from public meeting articles.
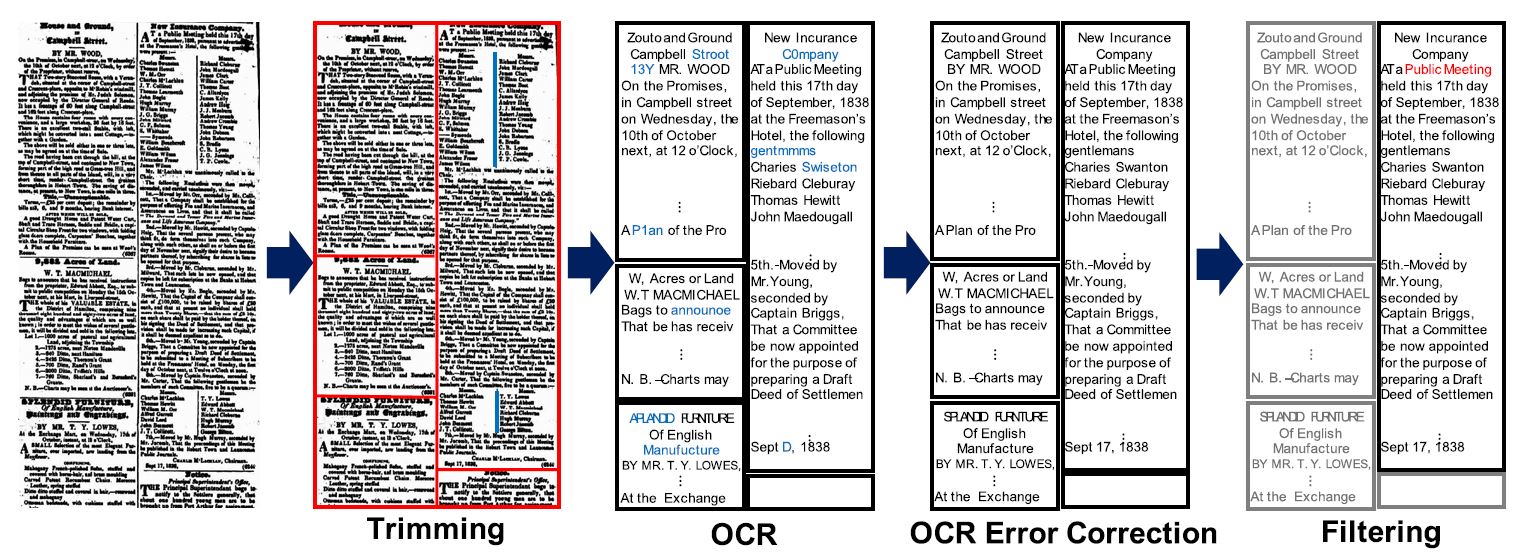
We annotated 1,258 public meeting articles with 6 questions for each article:
- q1: When was the public meeting being held?
- q2: Where was the place of the public meeting being held?
- q3: What was the purpose of the public meeting?
- q4: Who requested the convening of the public meeting?
- q5: Who was asked to convene the public meeting?
- q6: Who were convened to attend the public meeting?
Our dataset follows the same format as SQuAD 2.0.
If you use this dataset, please cite our paper "Felix Giovanni Virgo, Chenhui Chu, Takaya Ogawa, Koji Tanaka, Kazuki Ashihara, Yuta Nakashima, Noriko Takemura, Hajime Nagahara, Takao Fujikawa. Information Extraction from Public Meeting Articles. SN Computer Science, (2022)"
Bibtex for citations:
@Article{Virgo2022,
author={Virgo, Felix Giovanni and Chu, Chenhui and Ogawa, Takaya and Tanaka, Koji and Ashihara, Kazuki and Nakashima, Yuta and Takemura, Noriko and Nagahara, Hajime and Fujikawa, Takao},
title={Information Extraction from Public Meeting Articles},
journal={SN Computer Science},
year={2022},
month={May},
day={12},
volume={3},
number={4},
pages={285},
abstract={Public meeting articles are the key to understanding the history of public opinion and public sphere in Australia. Information extraction from public meeting articles can obtain new insights into Australian history. In this paper, we create an information extraction dataset in the public meeting domain. We manually annotate the date and time, place, purpose, people who requested the meeting, people who convened the meeting, and people who were convened of 1258 public meeting articles. We further present an information extraction system, which formulates information extraction from public meeting articles as a machine reading comprehension task. Experiments indicate that our system can achieve an F1 score of 74.98{\%} for information extraction from public meeting articles.},
issn={2661-8907},
doi={10.1007/s42979-022-01176-z},
url={https://doi.org/10.1007/s42979-022-01176-z}
}