Sephora adalah platform e-commerce yang dikenal secara luas sebagai salah satu toko kosmetik dan produk kecantikan terbesar dan terpercaya di dunia. Sephora menawarkan berbagai macam produk kecantikan termasuk skincare, makeup, perawatan rambut, parfum, dan masih banyak lagi dari berbagai merek terkenal dan berkualitas. Pelanggan dapat menemukan produk-produk terbaru, tren terkini, serta berbagai pilihan produk yang sesuai dengan preferensi dan kebutuhan mereka.
Pelanggan sering menghadapi tantangan dalam menemukan produk yang sesuai, seperti banyaknya pilihan, kompleksitas produk, ketersediaan informasi yang terbatas, dan kecepatan pencarian yang lambat. Untuk mengatasi tantangan ini, pengembangan sistem rekomendasi produk dapat membantu memberikan rekomendasi yang relevan dan personal kepada pelanggan, meningkatkan pengalaman berbelanja, dan mendorong peningkatan penjualan.
Proyek ini bertujuan mengembangkan sistem rekomendasi produk untuk Sephora. Fokus utama proyek ini adalah memberikan rekomendasi produk yang relevan dan personal kepada pelanggan Sephora berdasarkan preferensi dan karakteristik mereka. Dalam proyek ini, digunakan dua pendekatan berbeda, yaitu content-based filtering dan collaborative filtering [1].
Dalam content-based filtering, fitur-fitur produk diekstraksi menggunakan TF-IDF Vectorizer dan dijadikan vektor representasi. Kemudian, kemiripan antara vektor fitur dihitung dengan cosine similarity untuk merekomendasikan produk yang mirip dengan yang diminati pengguna. Collaborative filtering menggunakan data rating pengguna dan SVD untuk mengidentifikasi pola kesamaan antara pengguna. Dengan informasi ini, model merekomendasikan produk yang mendapatkan rating tinggi dari pengguna dengan preferensi serupa.
Beberapa penelitian sebelumnya telah dilakukan dalam bidang sistem rekomendasi produk dan menunjukkan hasil yang menjanjikan. Misalnya, dalam penelitian [2], mereka mengimplementasikan metode content-based filtering pada sistem rekomendasi produk kosmetik dan memberikan rekomendasi berdasarkan kebutuhan khusus pengguna. Penelitian lainnya [3] mencoba pendekatan collaborative filtering pada produk di platform e-commerce dengan menggunakan algoritma SVD dan menghasilkan nilai root mean square error (RMSE) sebesar 1.055586 dan dengan mengoptimalkan hyperparameter, mereka berhasil mendapatkan model dengan nilai RMSE sebesar 1.041784.
Dengan menggabungkan pengetahuan dari penelitian-penelitian sebelumnya, proyek ini bertujuan untuk mengembangkan sistem rekomendasi produk yang dapat memberikan rekomendasi yang lebih relevan dan personal kepada pelanggan. Dan diharapkan dapat meningkatkan pengalaman berbelanja pelanggan dan mendorong peningkatan penjualan produk.
Proyek ini bertujuan untuk mengembangkan sistem rekomendasi produk untuk toko online Sephora. Sephora adalah sebuah perusahaan kosmetik dan produk kecantikan yang terkenal dengan berbagai macam produk yang ditawarkan kepada pelanggan. Namun, dengan banyaknya pilihan produk yang tersedia, pelanggan seringkali kesulitan untuk menemukan produk yang sesuai dengan preferensi dan kebutuhan mereka. Proses pencarian produk yang memakan waktu lama juga dapat mengurangi kepuasan pelanggan dan efisiensi proses berbelanja. Oleh karena itu, tujuan utama proyek ini adalah untuk memberikan pengalaman belanja yang lebih baik kepada pelanggan dengan menyediakan rekomendasi produk yang relevan dan personal.
- Pelanggan Sephora kesulitan menemukan produk yang sesuai dengan preferensi dan karakteristik mereka di tengah banyaknya pilihan produk.
- Proses pencarian produk yang memakan waktu lama mengurangi kepuasan pelanggan dan efisiensi proses berbelanja.
- Mengembangkan sistem rekomendasi produk yang dapat memberikan rekomendasi yang relevan dan personal kepada pelanggan berdasarkan preferensi dan karakteristik mereka.
- Meningkatkan pengalaman berbelanja, kepuasan pelanggan, dan penjualan melalui pencarian yang lebih cepat, rekomendasi yang akurat, dan pengalaman berbelanja yang lebih baik.
Dengan mengembangkan sistem rekomendasi produk yang efektif, diharapkan Sephora dapat mengatasi tantangan yang dihadapi oleh pelanggan dalam menemukan produk yang sesuai dan meningkatkan pengalaman belanja mereka. Rekomendasi produk yang relevan dan personal akan membantu pelanggan menemukan produk yang sesuai dengan preferensi dan karakteristik mereka dengan lebih mudah dan cepat. Hal ini akan meningkatkan kepuasan pelanggan, efisiensi proses berbelanja, dan pada akhirnya, mendorong peningkatan penjualan produk di toko online Sephora.
- Mengimplementasikan metode content-based filtering dengan menggunakan TF-IDF Vectorizer untuk mengekstraksi fitur-fitur seperti bahan-bahan, kategori utama, dan kategori tersier dari setiap produk.
- Menghitung kemiripan antara vektor fitur produk menggunakan metode cosine similarity untuk merekomendasikan produk yang memiliki kesamaan tinggi dengan produk yang diminati oleh pengguna.
- Mengimplementasikan metode collaborative filtering dengan menggunakan teknik Singular Value Decomposition (SVD) untuk menganalisis perilaku rating pengguna terhadap produk.
- Mengidentifikasi pengguna dengan preferensi serupa berdasarkan data rating dan merekomendasikan produk yang mendapatkan rating tinggi dari pengguna-pengguna serupa tersebut.
Dataset yang digunakan dalam proyek ini diperoleh dari kumpulan data Kaggle yang berjudul "Sephora Products and Skincare Reviews". Dataset ini menyediakan informasi komprehensif tentang lebih dari 8.000 produk kecantikan yang tersedia di toko online Sephora. Dataset ini mencakup berbagai atribut untuk setiap produk, seperti nama produk, merek produk, harga, bahan-bahan, penilaian, dan fitur-fitur relevan lainnya.
Dataset yang digunakan dalam proyek ini yaitu: "product_info.csv" dan "reviews_1500_end.csv".
-
File "product_info.csv" memiliki 8.494 baris dan 27 kolom. Setiap baris mewakili sebuah produk kecantikan yang tersedia di toko online Sephora, dan kolom-kolomnya berisi informasi sebagai berikut:
product_id: ID unik untuk produk tersebut di situs webproduct_name: Nama lengkap produkbrand_id: Identifier unik untuk merek produk dari situs webbrand_name: Nama merek produkloves_countJumlah orang yang telah menandai produk ini sebagai favoritrating: Rating rata-rata produk berdasarkan ulasan penggunareviews: Jumlah ulasan pengguna untuk produk tersebutsize: Ukuran produk, dapat dalam oz, ml, g, paket, atau unit lain tergantung pada jenis produkvariation_type: Tipe parameter variasi untuk produkvariation_value: Nilai spesifik dari parameter variasi untuk produkvariation_desc: Deskripsi parameter variasi untuk produkingredients: Daftar bahan yang terkandung dalam produk.price_usd: Harga produk dalam dolar Amerika Serikatvalue_price_usd: Potensi penghematan biaya produk, ditampilkan di situs web di sebelah harga regulersale_price_usd: Harga jual produk dalam dolar Amerika Serikatlimited_edition: Menunjukkan apakah produk ini edisi terbatas atau tidaknew: Menunjukkan apakah produk ini baru atau tidakonline_only: Menunjukkan apakah produk ini hanya dijual secara online atau tidakout_of_stock: Menunjukkan apakah produk ini saat ini kosong atau tidaksephora_exclusive: Menunjukkan apakah produk ini eksklusif untuk Sephora atau tidakhighlights: Daftar tag atau fitur yang menyoroti atribut-atribut produkprimary_category: Kategori utama produksecondary_category: Kategori keduatertiary_category: Kategori tersier produkchild_count: Jumlah variasi produk yang tersediachild_max_price: Harga tertinggi di antara variasi produkchild_min_price: Harga terendah di antara variasi produk
Gambaran dataframe dari product_info.csv dapat dilihat pada Tabel 1. yang berisi beberapa data terkait rincian produk.
Tabel 1. Dataframe produk
| product_id | product_name | brand_id | brand_name | loves_count | rating | reviews | size | variation_type | variation_value | ... | online_only | out_of_stock | sephora_exclusive | highlights | primary_category | secondary_category | tertiary_category | child_count | child_max_price | child_min_price |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P473671 | Fragrance Discovery Set | 6342 | 19-69 | 6320 | 3.6364 | 11.0 | NaN | NaN | NaN | ... | 1 | 0 | 0 | ['Unisex/ Genderless Scent', 'Warm & Spicy Scen... | Fragrance | Value & Gift Sets | Perfume Gift Sets | 0 | NaN | NaN |
| P473668 | La Habana Eau de Parfum | 6342 | 19-69 | 3827 | 4.1538 | 13.0 | 3.4 oz/ 100 mL | Size + Concentration + Formulation | 3.4 oz/ 100 mL | ... | 1 | 0 | 0 | ['Unisex/ Genderless Scent', 'Layerable Scent'... | Fragrance | Women | Perfume | 2 | 85.0 | 30.0 |
| P473662 | Rainbow Bar Eau de Parfum | 6342 | 19-69 | 3253 | 4.25 | 16.0 | 3.4 oz/ 100 mL | Size + Concentration + Formulation | 3.4 oz/ 100 mL | ... | 1 | 0 | 0 | ['Unisex/ Genderless Scent', 'Layerable Scent'... | Fragrance | Women | Perfume | 2 | 75.0 | 30.0 |
-
File "reviews_1500_end.csv" terdiri dari 49.977 baris dan 3 kolom. Setiap baris mewakili ulasan pengguna untuk produk tertentu, dan kolom-kolomnya meliputi:
author_id: ID unik untuk penulis ulasan di situs webrating: Penilaian yang diberikan oleh penulis ulasan untuk produk dengan skala 1 hingga 5is_recommended: Menunjukkan apakah penulis merekomendasikan produk atau tidakhelpfulness: Rasio antara jumlah ulasan positif dan total ulasan: helpfulness = total_pos_feedback_count / total_feedback_counttotal_feedback_count: Jumlah total umpan balik (penilaian positif dan negatif) yang diberikan oleh pengguna untuk ulasantotal_neg_feedback_count: Jumlah pengguna yang memberikan penilaian negatif untuk ulasantotal_pos_feedback_count: Jumlah pengguna yang memberikan penilaian positif untuk ulasansubmission_time: Tanggal ulasan diposting di situs web dalam format 'yyyy-mm-dd'review_text: Teks utama dari ulasan yang ditulis oleh penulisreview_title: Judul ulasan yang ditulis oleh penulisskin_tone: Tone kulit penuliseye_color: Warna mata penulisskin_type: Tipe kulit penulishair_color: Warna rambut penulisproduct_id: ID unik untuk produk tersebut
Gambaran dataframe dari reviews_1500_end.csv dapat dilihat pada Tabel 2. yang berisi beberapa data terkait review pengguna.
Tabel 2. Dataframe review
| Unnamed: 0 | author_id | rating | is_recommended | helpfulness | total_feedback_count | total_neg_feedback_count | total_pos_feedback_count | submission_time | review_text | review_title | skin_tone | eye_color | skin_type | hair_color | product_id | product_name | brand_name | price_usd |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1945004256 | 5 | 1 | 1.0 | 0.000000 | 2 | 2 | 2022-12-10 | I absolutely L-O-V-E this oil. I have acne pro... | A must have! | lightMedium | green | combination | NaN | P379064 | Lotus Balancing & Hydrating Natural Face Treat... | Clarins | 65.0 |
| 1 | 5478482359 | 3 | 1 | 1.0 | 0.333333 | 3 | 2 | 2021-12-17 | I gave this 3 stars because it give me tiny li... | it keeps oily skin under control | mediumTan | brown | oily | black | P379064 | Lotus Balancing & Hydrating Natural Face Treat... | Clarins | 65.0 |
| 2 | 29002209922 | 5 | 1 | 1.0 | 1.000000 | 2 | 0 | 2021-06-07 | Works well as soon as I wash my face and pat d... | Worth the money! | lightMedium | brown | dry | black | P379064 | Lotus Balancing & Hydrating Natural Face Treat... | Clarins | 65.0 |
Pada proses preprocessing/cleaning, beberapa langkah telah dilakukan. Pertama, dipilih kolom-kolom yang relevan sesuai kebutuhan sistem rekomendasi yang akan dikembangkan. Pada file product_info.csv (dataframe produk), kolom yang dipilih antara lain product_id, product_name, brand_name, ingredients, primary_category, dan tertiary_category. Pemilihan kolom ini didasarkan pada kebutuhan model content-based filtering yang akan dikembangkan. Kolom-kolom tersebut penting untuk memberikan rekomendasi produk yang mirip dan sesuai dengan preferensi pengguna, dengan mempertimbangkan informasi mengenai bahan-bahan produk, kategori utama, dan kategori tertier. Selanjutnya, dilakukan penanganan terhadap data yang memiliki nilai null/missing value. Data dengan nilai null dihapus untuk memastikan data yang digunakan tidak memiliki nilai null yang dapat mempengaruhi model. Langkah selanjutnya adalah menangani data yang terduplikat. Dilakukan pengecekan terhadap adanya baris data yang memiliki nilai yang sama pada seluruh kolom. Jika terdapat duplikasi, baris data tersebut dihapus untuk menjaga kebersihan data dan mencegah bias yang tidak diinginkan. Contoh dataframe produk yang telah dibersihkan dapat dilihat pada Tabel 3.
Tabel 3. Dataframe produk
| product_id | product_name | brand_name | ingredients | primary_category | tertiary_category |
|---|---|---|---|---|---|
| P473671 | Fragrance Discovery Set | 19-69 | ['Capri Eau de Parfum:', 'Alcohol Denat. (SD A... | Fragrance | Perfume Gift Sets |
| P473668 | La Habana Eau de Parfum | 19-69 | ['Alcohol Denat. (SD Alcohol 39C), Parfum (Fra... | Fragrance | Perfume |
| P473662 | Rainbow Bar Eau de Parfum | 19-69 | ['Alcohol Denat. (SD Alcohol 39C), Parfum (Fra... | Fragrance | Perfume |
Untuk file reviews_1500_end.csv (dataframe review), juga dilakukan proses preprocessing/cleaning yang sama. Pada file ini, kolom-kolom yang digunakan adalah author_id, product_id, dan rating. Pemilihan kolom-kolom ini didasarkan pada pengembangan model collaborative filtering yang memanfaatkan data rating produk dari pengguna atau penulis ulasan. Kolom author_id digunakan untuk mengidentifikasi secara unik penulis ulasan, sementara kolom product_id digunakan untuk mengidentifikasi produk yang diberi ulasan. Rating merupakan nilai penilaian yang diberikan oleh penulis ulasan terhadap produk tersebut. Dengan menggunakan kolom-kolom ini, dapat diidentifikasi pola kesamaan antara pengguna berdasarkan preferensi produk yang mereka berikan. Proses preprocessing/cleaning yang dilakukan pada file reviews_1500_end.csv mirip dengan langkah-langkah pada file product_info.csv. Data dengan nilai null dan duplikat dihapus untuk menjaga kualitas dan kebersihan data. Contoh dataframe review yang telah dibersihkan dapat dilihat pada Tabel 4.
Tabel 4. Dataframe Review
| author_id | product_id | rating |
|---|---|---|
| 1945004256 | P379064 | 5 |
| 5478482359 | P379064 | 3 |
| 29002209922 | P379064 | 5 |
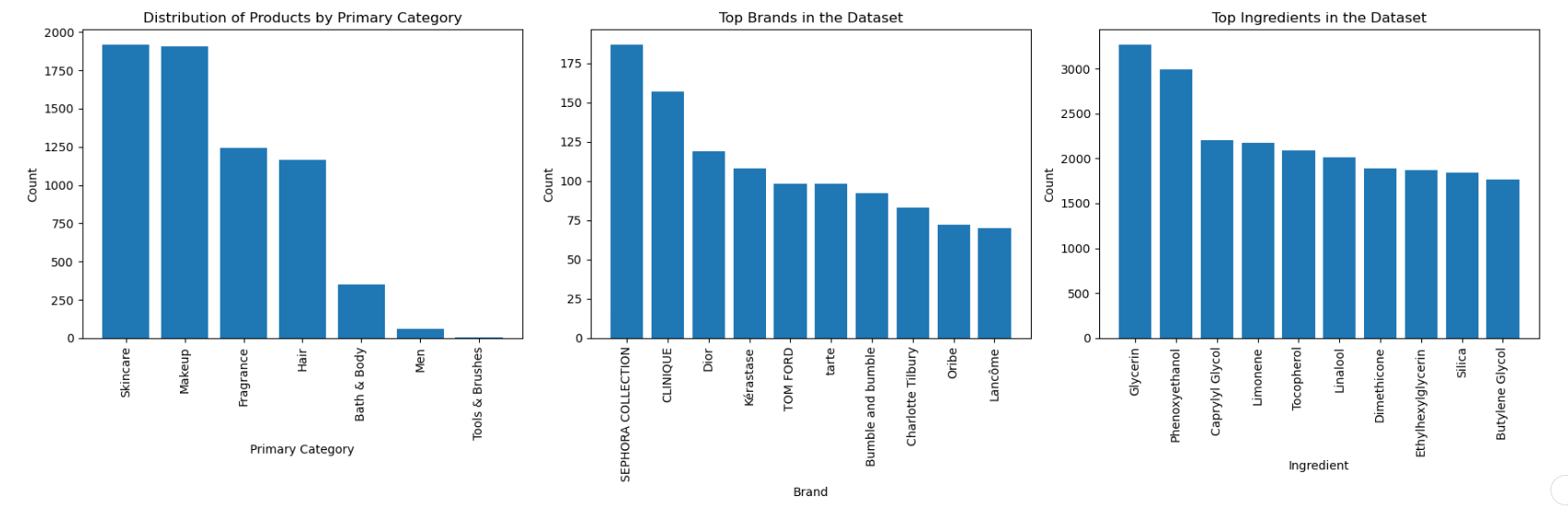
Pada dataframe produk dilakukan eksplorasi terhadap atribut-atribut seperti nama produk, merek produk, harga, bahan-bahan, kategori utama, dan kategori tersier. Pada tahap ini dapat dilihat distribusi produk per kategori utama, top-10 brand, top-10 ingredient semua product pada Gambar 1. Temuan yang didapatkan adalah:
- Distribusi Produk per Kategori Utama: Produk skincare dan makeup mendominasi jumlah produk yang tersedia di Sephora.
- Top-10 Brand: Sephora Collection dan Clinique adalah brand yang paling banyak menghadirkan produk dalam dataset.
- Top-10 Bahan (Ingredient): Glycerin dan phenoxyethanol adalah bahan yang paling sering digunakan dalam produk.
Dengan memanfaatkan temuan-temuan dari EDA, diharapkan model content-based filtering yang dikembangkan mampu memberikan rekomendasi produk yang lebih relevan dan sesuai dengan preferensi pengguna yang didasarkan pada kategori utama, brand, dan bahan yang disukai oleh pengguna.
 Gambar 1. EDA Produk
Gambar 1. EDA Produk
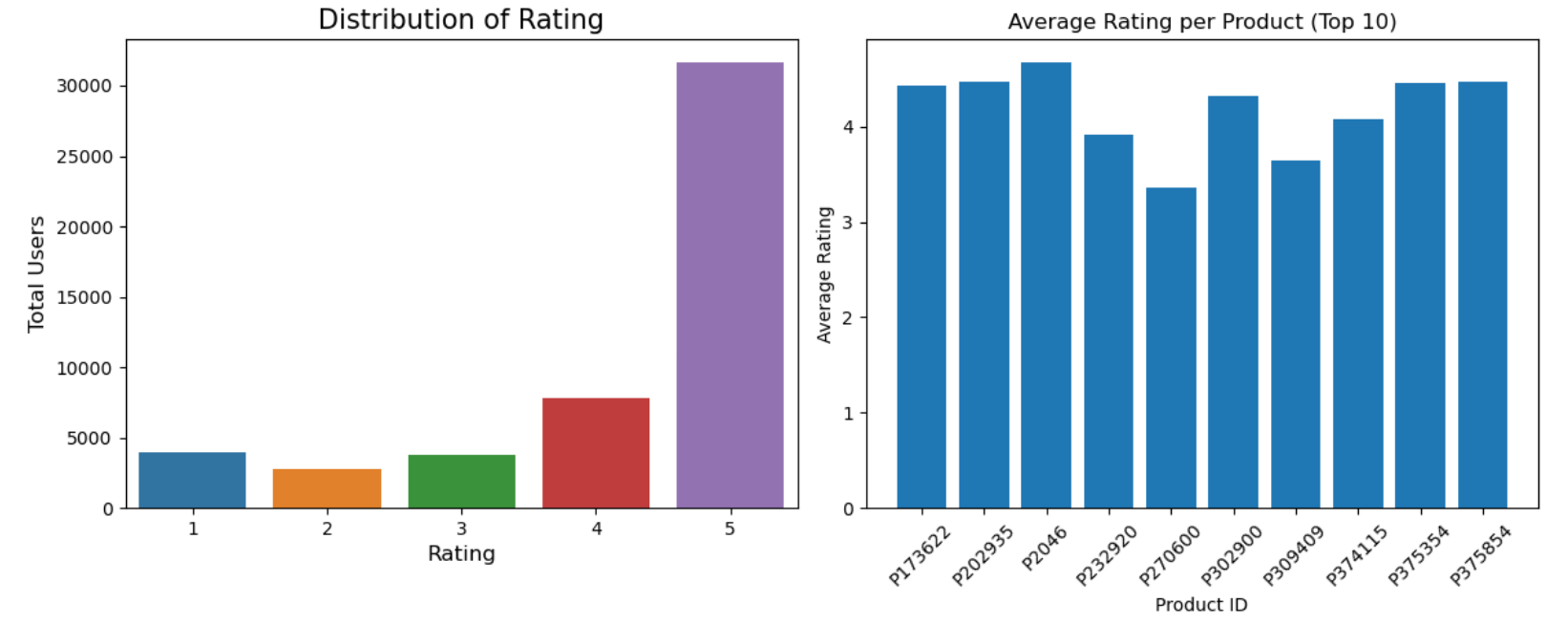
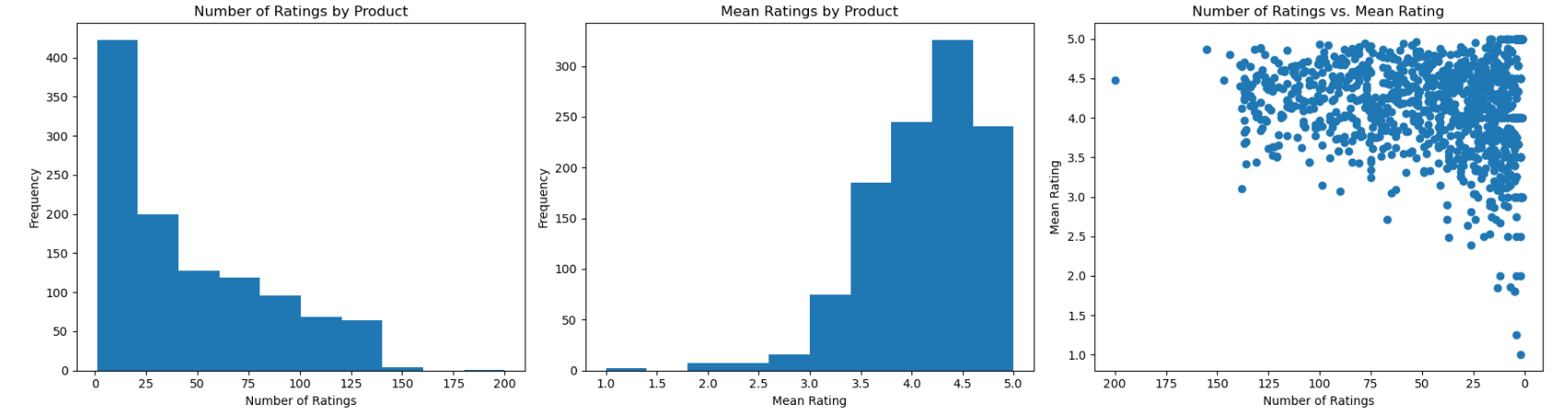
Pada file "reviews.csv", analisis data eksploratori dilakukan terhadap atribut-atribut seperti ID penulis ulasan, ID produk, dan rating yang diberikan oleh penulis. Pada tahap ini, dapat dilihat distribusi rating, rata-rata rating per product, jumlah rating per product, rata-rata rating pada Gambar 2 dan 3. Temuan yang didapatkan adalah:
- Distribusi rating: lebih dari 30.000 pengguna memberikan rating 5 untuk produk. Hal ini menunjukkan bahwa banyak pengguna memberikan rating tinggi (5) untuk produk yang ada dalam dataset.
- Rata-rata rating per product: rata-rata produk memiliki rating yang bagus. Meskipun ada produk dengan rating yang rendah, secara umum, rata-rata rating produk cenderung tinggi. Ini menunjukkan bahwa sebagian besar produk dalam dataset memiliki rating yang baik.
Dengan memanfaatkan temuan-temuan dari EDA, diharapkan model collaborative filtering yang dikembangkan mampu memberikan rekomendasi produk yang lebih relevan dan sesuai dengan preferensi pengguna berdasarkan rating yang diberikan oleh pengguna lain terhadap produk.
 Gambar 2. EDA Review part 1
Gambar 2. EDA Review part 1
 Gambar 3. EDA Review part 2
Gambar 3. EDA Review part 2
Content-based filtering adalah metode dalam sistem rekomendasi yang menggunakan kesamaan atribut atau konten dari produk yang telah disukai atau dilihat oleh pengguna sebelumnya. Sistem menganalisis atribut produk seperti deskripsi, fitur, kategori, dan metadata lainnya. Profil pengguna dibangun berdasarkan preferensi atau interaksi dengan produk, lalu sistem mencari kesamaan antara atribut produk dalam profil pengguna dan database produk [1][2].
Feature Engineering:
Metode content-based filtering dikembangkan dengan menggunakan algoritma TF-IDF (Term Frequency-Inverse Document Frequency) untuk mengekstraksi fitur-fitur dari produk. Fitur-fitur yang diekstraksi meliputi bahan-bahan, kategori utama, dan kategori tersier. Setelah itu, fitur -fitur tersebut digabungkan menjadi satu vektor representasi menggunakan hstack. Hal ini bertujuan untuk menggabungkan informasi dari berbagai atribut produk menjadi satu representasi fitur yang komprehensif.
Model TF-IDF adalah sebuah metode analisis yang mengevaluasi seberapa relevan suatu kata dalam sebuah dokumen dalam kumpulan dokumen. TF-IDF merupakan gabungan dari dua metode ekstraksi, yaitu TF (Term Frequency) dan IDF (Inverse Document Frequency). TF menghitung seberapa sering sebuah kata muncul dalam suatu dokumen dan IDF menghitung seberapa umum atau langka sebuah kata dalam seluruh kumpulan dokumen, sehingga mengetahui pentingnya sebuah kata [4].
Similarity Calculation:
Selanjutnya, dilakukan perhitungan kemiripan menggunakan metode cosine similarity. Metode ini digunakan untuk mengukur sejauh mana dua vektor fitur tersebut mirip satu sama lain. Hasilnya adalah matriks kemiripan yang menunjukkan tingkat kemiripan antara setiap pasang produk dalam dataset. Hasil dari matrix similarity menggunakan cosine similarity dapat dilihat pada Tabel 5.
Cosine similarity adalah metode untuk mengukur tingkat kesamaan antara dua vektor. Dalam konteks dokumen, cosine similarity digunakan untuk membandingkan kesamaan antara dua dokumen berdasarkan representasi vektor dari dokumen-dokumen tersebut [2].
Rumus perhitungan cosine similarity:
cosine similarity (x, y) = Σ(xi * yi) / (√(Σ(xi^2)) * √(Σ(yi^2)))
Di mana:
- x dan y adalah dua vektor yang akan dibandingkan.
- xi adalah elemen ke-i pada vektor x.
- yi adalah elemen ke-i pada vektor y.
Perhitungan cosine similarity melibatkan perkalian dan penjumlahan elemen-elemen vektor, yang kemudian dibagi dengan perkalian magnitudo masing-masing vektor. Hasil perhitungan cosine similarity berada dalam rentang -1 hingga 1. Nilai yang mendekati 1 menunjukkan tingkat kesamaan yang tinggi antara dua vektor, sementara nilai yang mendekati -1 menunjukkan perbedaan yang besar. Nilai yang mendekati 0 menunjukkan bahwa dua vektor tidak memiliki kesamaan yang signifikan.
Tabel 5. Hasil matrix similarity menggunakan cosine similarity
| product_id | P500606 | P483662 | P430910 | P501687 | P442734 |
|---|---|---|---|---|---|
| P469102 | 0.006751 | 0.000000 | 0.030293 | 0.039041 | 0.015038 |
| P397665 | 0.031275 | 0.040026 | 0.010865 | 0.005701 | 0.034023 |
| P481377 | 0.007799 | 0.007605 | 0.334685 | 0.340024 | 0.006125 |
| P461600 | 0.506776 | 0.466299 | 0.005326 | 0.005960 | 0.031491 |
| P422905 | 0.016008 | 0.011395 | 0.017614 | 0.018594 | 0.379430 |
| P482263 | 0.444789 | 0.410472 | 0.002666 | 0.000000 | 0.017110 |
| P479734 | 0.017136 | 0.050994 | 0.017292 | 0.011651 | 0.365741 |
| P457828 | 0.463426 | 0.458255 | 0.000568 | 0.000000 | 0.114641 |
| P474824 | 0.017567 | 0.010696 | 0.019336 | 0.013645 | 0.710104 |
| P17876556 | 0.351651 | 0.341904 | 0.006136 | 0.008798 | 0.030991 |
Top-10 Recommmendation (Example Usage):
Kemudian dibuat fungsi untuk menghasilkan rekomendasi produk berdasarkan produk yang diberikan dengan menghitung kemiripan antara produk yang diberikan dengan produk lain dalam dataset, dan mengambil produk dengan kemiripan tertinggi sebagai rekomendasi. Berikut contoh hasil top-10 rekomendasi produk berdasarkan produk dengan ID tertentu.
Tabel 6. Informasi produk (example usage)
| product_name | brand_name | primary_category | tertiary_category |
|---|---|---|---|
| Fragrance Discovery Set | 19-69 | Fragrance | Perfume Gift Sets |
Tabel 7. Top-10 Recommendation: Content-Based Filtering
| rank | product_name | brand_name | primary_category | tertiary_category |
|---|---|---|---|---|
| 1 | Wild Poppy Perfume Set | NEST New York | Fragrance | Perfume Gift Sets |
| 2 | Sunkissed Hibiscus Fine Fragrance Set | NEST New York | Fragrance | Perfume Gift Sets |
| 3 | Not a Perfume Sampler Set | Juliette Has a Gun | Fragrance | Perfume Gift Sets |
| 4 | Essential Wardrobe Eau de Parfum Set | Juliette Has a Gun | Fragrance | Perfume Gift Sets |
| 5 | Mini Fragrance Discovery Set | HERMÈS | Fragrance | Perfume Gift Sets |
| 6 | Dylan Blue & Dylan Turquoise Travel Spray Duo Set | Versace | Fragrance | Perfume Gift Sets |
| 7 | Mini Perfume Set | Versace | Fragrance | Perfume Gift Sets |
| 8 | Archive Kit Sampler Set | Commodity | Fragrance | Perfume Gift Sets |
| 9 | Fragrance Discovery Set | Boy Smells | Fragrance | Perfume Gift Sets |
| 10 | Mini Good Girl Perfume Set | Carolina Herrera | Fragrance | Perfume Gift Sets |
Collaborative filtering adalah metode dalam sistem rekomendasi yang menggunakan informasi dari pengguna lain untuk memberikan rekomendasi kepada pengguna. Metode ini mengidentifikasi pengguna dengan preferensi atau perilaku serupa, dan menggunakan informasi dari pengguna-pengguna tersebut untuk meramalkan preferensi atau rekomendasi bagi pengguna target [1][3].
SVD (Singular Value Decomposition):
SVD (Singular Value Decomposition) adalah teknik untuk memecah sebuah matriks menjadi tiga matriks terpisah: U, Σ, dan V. Matriks Σ berisi nilai-nilai singular yang menunjukkan signifikansi dari vektor singular. SVD digunakan untuk mengurangi dimensi data dan menangkap informasi penting dalam matriks asli. Rumus SVD adalah A = UΣV^T, di mana U dan V adalah matriks singular kiri dan kanan, dan Σ adalah matriks diagonal dengan nilai-nilai singular [3].
Pelatihan model collaborative filtering dilakukan menggunakan algoritma SVD. Dataset dibagi menjadi set pelatihan dan pengujian menggunakan fungsi train_test_split dari pustaka Surprise. Pertama, model SVD dilatih dengan menggunakan cross-validation. Kemudian model SVD tersebut dilatih menggunakan keseluruhan trainset. Metrik evaluasi yang digunakan adalah RMSE (Root Mean Square Error) dan MAE (Mean Absolute Error), yang mengukur keakuratan prediksi model dibandingkan dengan rating sebenarnya.
Hyperparameter Tuning:
Untuk mengoptimalkan model SVD, dilakukan hyperparameter tuning menggunakan GridSearchCV dari pustaka Surprise. GridSearchCV digunakan untuk mencari kombinasi hiperparameter terbaik yang meminimalkan skor RMSE dan MAE. Hiperparameter yang dipertimbangkan dalam proses penyetelan meliputi n_factor, epoch, lr_all (tingkat pembelajaran), dan reg_all (tingkat regularisasi). Hiperparameter terbaik yang ditemukan melalui penyetelan adalah n_factor sebesar 50, epoch sebesar 50, lr_all sebesar 0.01, dan reg_all sebesar 0.1. Model SVD kemudian dilatih dengan seluruh trainset menggunakan hiperparameter optimal ini.
Top-10 Recommmendation (Example Usage):
Kemudian dibuat fungsi untuk menghasilkan rekomendasi produk berdasarkan pengguna spesifik dengan memprediksi rating untuk produk-produk yang belum dinilai oleh pengguna tersebut. Prediksi tersebut akan diurutkan secara menurun. Berikut contoh hasil top-10 rekomendasi produk berdasarkan pengguna dengan ID tertentu.
Tabel 8. Produk yang diberi rating tinggi oleh user 1845533064
| Product ID | Product Name | Primary Category | Rating |
|---|---|---|---|
| P480608 | Equilibrium Instant Plumping Eye Mask | Skincare | 4 |
| P504277 | Face Stone Nourishing Solid Refillable Facial Oil with Tamanu + Blue Tansy | Skincare | 4 |
| P504506 | The Silk Serum Wrinkle-Smoothing Retinol Alternative | Skincare | 5 |
| P502741 | SuperSolutions 10% Azelaic Serum Redness Relief Solution | Skincare | 5 |
| P483701 | Daily Essentials Travel Set | Skincare | 5 |
Tabel 9. Top-10 Recommendation: Collaborative Filtering
| Rank | Product ID | Product Name | Primary Category |
|---|---|---|---|
| 1 | P500983 | Anytime, Anyface Lactic Acid Serum + Protini Moisturizer Duo | Skincare |
| 2 | P505338 | Pore Perfecting Liquid Exfoliator with 2% BHA + Borage | Skincare |
| 3 | P505316 | Aquarius BHA + Blue Tansy Clarity Cleanser | Skincare |
| 4 | P476496 | Instant Reset Brightening Overnight Recovery Gel-Cream with Niacinamide Refill | Skincare |
| 5 | P505133 | High Performance Face Cleanser for Clear Skin with Niacinamide | Skincare |
| 6 | P474057 | Lip Service - Lip Balm Duo Mint & Shea | Skincare |
| 7 | P467112 | Daily Microfoliant Exfoliator Refill Pack | Skincare |
| 8 | P505381 | Multi Action Clear Gentle Daily Brightening & Retexturizing Toner for Acne and Breakouts | Skincare |
| 9 | P504049 | Skin Filter Daily Brightening Phyto-Retinol + AHA Serum | Skincare |
| 10 | P419466 | Tan Build Up Remover Mitt | Skincare |
Model content-based filtering yang dikembangkan berhasil memberikan rekomendasi produk yang sangat relevan dengan preferensi pengguna berdasarkan kategori dan subkategori yang diinginkan. Dengan presisi sebesar 100%, model ini mampu memberikan rekomendasi produk yang sesuai dan dapat diandalkan.
Perhitungan presisi dilakukan menggunakan formula berikut:
Precision = (# of our recommendations that are relevant) / (# of items we recommended)
Berdasarkan contoh penggunaan (example usage):
Precision = rekomendasi relevan (fragrance & Perfume Gift Sets) / banyak rekomendasi
Precision = 10 / 10 = 1
Jadi presisinya = 100%
Dalam konteks ini, precision mengukur persentase rekomendasi yang relevan dengan preferensi pengguna terhadap kategori dan subkategori produk yang sama. Dalam kasus ini, semua rekomendasi yang diberikan oleh model memiliki kategori dan subkategori yang sama dengan contoh penggunaan (example usage), sehingga presisinya adalah 100%. Hal ini menunjukkan bahwa model memberikan rekomendasi yang tepat dan relevan dengan preferensi pengguna.
Evaluasi model collaborative filtering dilakukan untuk mengukur kinerja dan akurasi model dalam memberikan rekomendasi produk kepada pengguna. Terdapat beberapa metrik evaluasi yang umum digunakan:
-
Root Mean Square Error (RMSE): Metrik ini mengukur perbedaan antara rating yang diprediksi oleh model dengan rating sebenarnya. RMSE menghitung akar dari rata-rata dari kuadrat selisih antara rating prediksi dan rating sebenarnya. Semakin rendah nilai RMSE, semakin baik model dalam memprediksi rating.
-
Mean Absolute Error (MAE): Metrik ini juga mengukur perbedaan antara rating prediksi dan rating sebenarnya, tetapi tanpa memperhatikan arah perbedaan. MAE menghitung rata-rata dari selisih absolut antara rating prediksi dan rating sebenarnya. Nilai MAE yang lebih rendah menunjukkan kinerja model yang lebih baik.
-
Precision, Recall, dan F1-Score: Precision mengukur sejauh mana produk yang direkomendasikan benar-benar relevan bagi pengguna. Recall mengukur sejauh mana produk yang relevan berhasil ditemukan oleh model. F1-Score adalah ukuran kombinasi dari precision dan recall. Semakin tinggi nilai precision, recall, dan F1-Score, semakin baik kinerja model dalam memberikan rekomendasi yang relevan.
Hasil evaluasi yang diperoleh adalah sebagai berikut:
Tabel 10. Hasil evaluasi model SVD pada data uji (full trainset)
| Metrics | Tanpa Hyperparameter Tuning | Dengan Hyperparameter Tuning |
|---|---|---|
| RSME (Root Mean Squared Error) | 0.7998 | 0.3348 |
| MAE (Mean Absolute Error) | 0.6083 | 0.2539 |
| Precision | 0.9194 | 0.9946 |
| Recall | 0.9983 | 0.9978 |
| F1-score | 0.9572 | 0.9962 |
Hasil evaluasi menggunakan model SVD pada data uji (dengan ,enggunakan full trainset) menunjukkan bahwa penggunaan hyperparameter tuning memiliki dampak positif terhadap kualitas prediksi. Model dengan hyperparameter tuning menghasilkan nilai RMSE dan MAE yang lebih rendah, menandakan kemampuan yang lebih baik dalam memperkirakan rating yang sebenarnya. Selain itu, terdapat peningkatan yang signifikan dalam presisi, recall, dan F1-score, yang meunjukkan kemampuan yang lebih baik dalam mengklasifikasikan ulasan dan memberikan rekomendasi produk yang lebih relevan. Oleh karena itu, penerapan hyperparameter tuning pada model SVD dapat meningkatkan akurasi dan kualitas sistem rekomendasi produk, yang berpotensi meningkatkan kepuasan pelanggan dan penjualan.
Dengan demikian, hasil evaluasi menunjukkan bahwa penerapan hyperparameter tuning pada model collaborative filtering memiliki dampak positif terhadap kualitas sistem rekomendasi. Dengan nilai presisi yang tinggi, sistem mampu memberikan rekomendasi produk yang relevan bagi pengguna. Selain itu, peningkatan presisi, recall, dan F1-score juga menunjukkan bahwa model dapat dengan akurat mengklasifikasikan rating dan menghasilkan rekomendasi yang sesuai.
Hasil evaluasi kedua model ini memiliki implikasi yang signifikan terhadap kualitas sistem rekomendasi. Dengan akurasi yang lebih tinggi, sistem dapat memberikan rekomendasi produk yang lebih relevan dan sesuai dengan preferensi pengguna. Hal ini dapat meningkatkan kepuasan pengguna, meningkatkan retensi pelanggan, dan berpotensi meningkatkan penjualan produk.
Dalam proyek pengembangan sistem rekomendasi produk untuk toko online Sephora, telah diimplementasikan dua pendekatan: content-based filtering dan collaborative filtering. Pendekatan content-based filtering menggunakan TF-IDF Vectorizer untuk mengekstraksi fitur-fitur produk dan menghitung kemiripan antara produk menggunakan metode cosine similarity. Pendekatan collaborative filtering menggunakan metode Singular Value Decomposition (SVD) untuk menganalisis perilaku rating pengguna.
Melalui evaluasi model, hasilnya menunjukkan bahwa penggunaan cosine similarity dalam content-based filtering mampu memberikan rekomendasi produk yang relevan dengan preferensi pengguna. Selain itu, melalui hyperparameter tuning pada model SVD, diperoleh model dengan performa yang lebih baik dalam memprediksi rating dan memberikan rekomendasi produk.
Dengan penerapan sistem rekomendasi ini, diharapkan dapat meningkatkan pengalaman berbelanja pelanggan dengan rekomendasi yang akurat dan personal. Hal ini berpotensi meningkatkan kepuasan pelanggan, penjualan, dan retensi pelanggan di toko online Sephora.
[1] Abdul Hussien, Farah Tawfiq, et al. “Recommendation Systems for E-Commerce Systems an Overview.” Journal of Physics: Conference Series, vol. 1897, no. 1, 1 May 2021, p. 012024, https://doi.org/10.1088/1742-6596/1897/1/012024.
[2] Patty, Joanna, et al. “Recommendations System for Purchase of Cosmetics Using Content- Based Filtering.” International Journal of Computer Engineering and Information Technology, vol. 10, no. 1, 2018, pp. 1–5, www.ijceit.org/published/volume10/issue1/1Vol10No1.pdf. Accessed 10 July 2023.
[3] Shalannanda, Wervyan, et al. “Singular Value Decomposition Model Application for E-Commerce Recommendation System.” JITEL (Jurnal Ilmiah Telekomunikasi, Elektronika, Dan Listrik Tenaga), vol. 2, no. 2, 30 Sept. 2022, pp. 103–110, https://doi.org/10.35313/jitel.v2.i2.2022.103-110. Accessed 7 Apr. 2023.
[4] Yeruva, Sagar, et al. “Apparel Recommendation System Using Content-Based Filtering.” International Journal of Recent Technology and Engineering (IJRTE), vol. 11, no. 4, 30 Nov. 2022, pp. 46–51, https://doi.org/10.35940/ijrte.d7331.1111422. Accessed 13 Feb. 2023.