![]()
Official PyTorch implementation of Pruner-Zero, accepted by ICML2024
Pruner-Zero: Evolving Symbolic Pruning Metric from scratch for Large Language Models
Peijie Dong*, Lujun Li* ( indicates equal contribution), Zhenheng Tang, Xiang Liu, Xinglin Pan, Qiang Wang, Xiaowen Chu
HKUST(GZ), HKUST, HKBU, HIT(SZ)
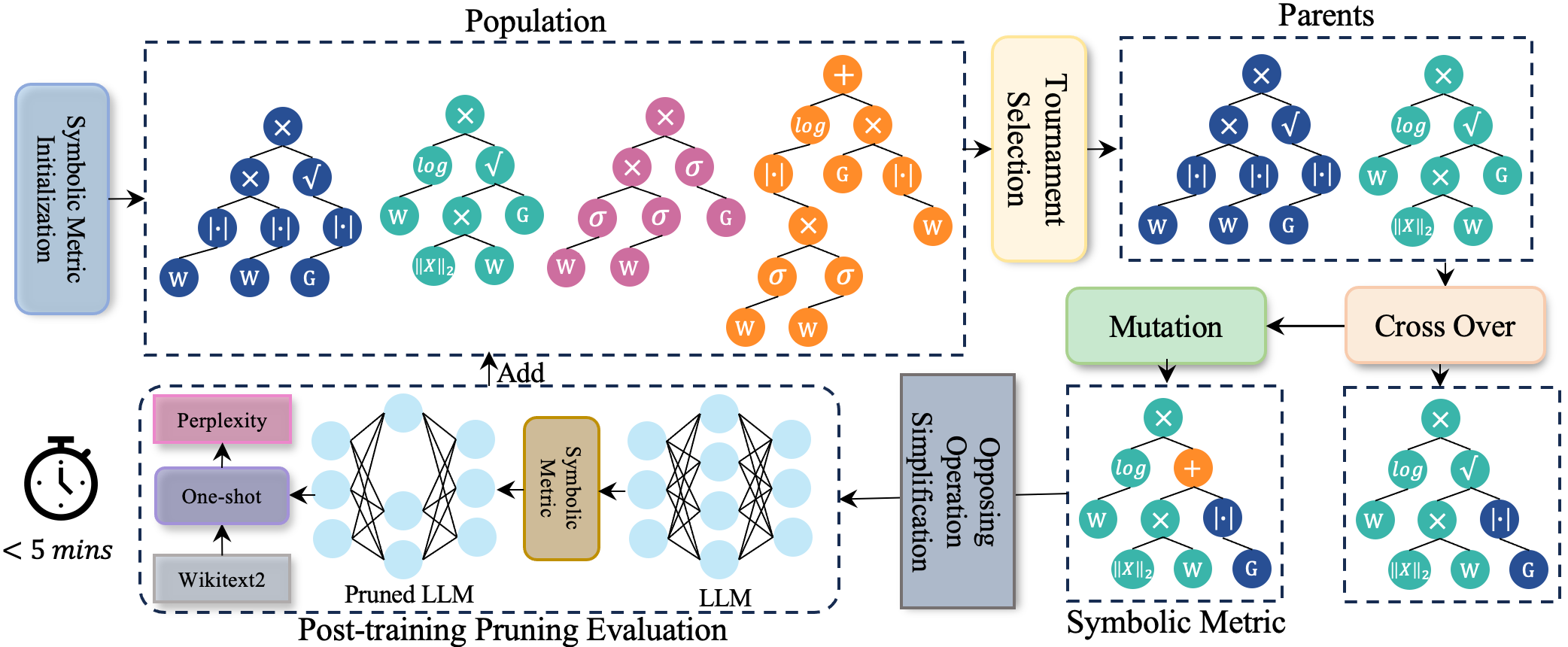
Despite the remarkable capabilities, Large Language Models (LLMs) face deployment challenges due to their extensive size. Pruning methods drop a subset of weights to accelerate, but many of them require retraining, which is prohibitively expensive and computationally demanding. Recently, post-training pruning approaches introduced novel metrics, enabling the pruning of LLMs without retraining. However, these metrics require the involvement of human experts and tedious trial and error. To efficiently identify superior pruning metrics, we develop an automatic framework for searching symbolic pruning metrics using genetic programming. In particular, we devise an elaborate search space encompassing the existing pruning metrics to discover the potential symbolic pruning metric. We propose an opposing operation simplification strategy to increase the diversity of the population. In this way, Pruner-Zero allows auto-generation of symbolic pruning metrics. Based on the searched results, we explore the correlation between pruning metrics and performance after pruning and summarize some principles. Extensive experiments on LLaMA and LLaMA-2 on language modeling and zero-shot tasks demonstrate that our Pruner-Zero obtains superior performance than SOTA post-training pruning methods.
Installation instructions can be found in INSTALL.md.
Our method require computation of gradient magnitude for calculation of pruning metric, following GBLM-Pruner. For more scripts, see grad_computation.sh
# Demo for OPT
CUDA_VISIBLE_DEVICES=0 python lib/gradient_computation.py --nsamples 128 \
--model /path/to/facebook/opt-125m --llama_version 2 --task gradient
# Demo for LLama-1
CUDA_VISIBLE_DEVICES=0,1 python lib/gradient_computation.py --nsamples 1 \
--model $PATH_TO_LLAMA1 --llama_version 1 --task gradient
# Demo for LLama-2
CUDA_VISIBLE_DEVICES=0,1 python lib/gradient_computation.py --nsamples 128 \
--model $PATH_TO_LLAMA2 --llama_version 2 --task gradientBelow is an example command for pruning LLaMA-7B with Pruner-Zero, to achieve unstructured 50% sparsity.
python main.py \
--model decapoda-research/llama-7b-hf \
--prune_method pruner-zero \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--save out/llama_7b/unstructured/pruner-zero/ We provide a quick overview of the arguments:
--model: The identifier for the LLaMA model on the Hugging Face model hub.--cache_dir: Directory for loading or storing LLM weights. The default isllm_weights.--prune_method: We have implemented three pruning methods, namely [magnitude,wanda,sparsegpt,pruner-zero].--sparsity_ratio: Denotes the percentage of weights to be pruned.--sparsity_type: Specifies the type of sparsity [unstructured,2:4,4:8].--save: Specifies the directory where the result will be stored.
For structured N:M sparsity, set the argument --sparsity_type to "2:4" or "4:8". An illustrative command is provided below:
python main.py \
--model decapoda-research/llama-7b-hf \
--prune_method pruner-zero \
--sparsity_ratio 0.5 \
--sparsity_type 2:4 \
--save out/llama_7b/2-4/pruner-zero/ For LLaMA-2 models, replace --model with meta-llama/Llama-2-7b-hf (take 7b as an example):
python main.py \
--model meta-llama/Llama-2-7b-hf \
--prune_method pruner-zero \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--save out/llama2_7b/unstructured/pruner-zero/{
"data": "mul",
"left": {
"data": "abs",
"left": {
"data": "mul",
"left": {
"data": "W"
},
"right": {
"data": "W"
}
}
},
"right": {
"data": "mms",
"left": {
"data": "G"
}
}
}For evaluating zero-shot tasks, we modify the EleutherAI LM Harness framework so that it could evaluate pruned LLM models. We provide the modified repo in this link. Make sure to download, extract and install this custom lm_eval package from the source code.
For reproducibility, we used commit df3da98 on the main branch. All tasks were evaluated on task version of 0 except for BoolQ, where the task version is 1.
On a high level, the functionality we provide is adding two arguments pretrained_model and tokenizer in this function. We can then call this simple_evaluate function API from our codebase to evaluate sparse pruned LLMs. To evaluate zero-shot tasks in addition to the WikiText perplexity, pass the --eval_zero_shot argument.
This repository is build upon the SparseGPT, Wanda and GBLM-Pruner repository.
This project is released under the MIT license. Please see the LICENSE file for more information.
@inproceedings{dong2024pruner,
title={Pruner-Zero: Evolving Symbolic Pruning Metric from Scratch for Large Language Models},
author={Dong, Peijie and Li, Lujun and Tang, Zhenheng and Liu, Xiang and Pan, Xinglin and Wang, Qiang and Chu, Xiaowen},
booktitle={Proceedings of the 41st International Conference on Machine Learning},
year={2024},
organization={PMLR},
url={https://arxiv.org/abs/2406.02924},
note={[arXiv: 2406.02924]}
}