Python implementation of the Extended Collaborative Less-isMore Filtering, a CLiMF evolution to allow using multiple levels of relevance data. Both algorithms are a variante of Latent factor CF, wich optimises a lower bound of the smoothed reciprocal rank of "relevant" items in ranked recommendation lists.
CLiMF: Learning to Maximize Reciprocal Rank with Collaborative Less-is-More Filtering Yue Shi, Martha Larson, Alexandros Karatzoglou, Nuria Oliver, Linas Baltrunas, Alan Hanjalic ACM RecSys 2012
CLiMF implementation that this xCLiMF implementation is based: https://github.com/gamboviol/climf (This CLiMF implementation has this bug: gamboviol/climf#2)
xCLiMF: Optimizing Expected Reciprocal Rank for Data with Multiple Levels of Relevance Yue Shia, Alexandros Karatzogloub, Linas Baltrunasb, Martha Larsona, Alan Hanjalica ACM RecSys 2013
xCLiMF implementation that have been consulted: https://github.com/gpoesia/xclimf (with this bug: gpoesia/xclimf#1)
-
Runned Grid Search for movie lens 20m dataset ( https://grouplens.org/datasets/movielens/20m/ ). Got as best cross validation MRR: 0.008 using D=15, lambda=0.001, gamma=0.0001.
python -u grid_search.py --dataset ../ml-20m/ratings.csv --sep , --skipfl -
Runned XClimf with hyperparameters tunned by Grid Search on movie lens 20m dataset, but got math range error
python -u xclimf.py --dataset ../ml-20m/ratings.csv --sep , --skipfl --dim 15 --lambda 0.001 --gamma 0.0001 -
After debugging, found some differences between paper and implementation. Tryied exactly same experimentantion protocol described in the paper using random disjoint ratings for each user in training and testing dataset (protocol that i strongly disagree). Got again math range error.
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.001 --dim 10 --seltype random -
Found some combinations of the random latent features initialization U and V that causes bigger results in first step of gradient ascending. These results causes the math range error in the objective function. Using a gamma like 1e-7 made me get a MRR of 0.028, but we can observe that the objective function is not ascending.
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 1e-7 --dim 10 --seltype random -
Experimented gamma 1e-6 and got a worst MRR: 0.021
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 1e-6 --dim 10 --seltype random -
Tried normalizing rating as r/max(r), using gamma like described in paper, and got: MRR: 0.068
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.001 --dim 10 --seltype random --norm -
Since MRR was getting high slowly, I tried a bigger gamma of 0.1, but got divide by zero and math domain error
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.1 --dim 10 --seltype random --norm -
Repeated gamma 0.001 with 500 iteractions, stopying when get the maximum objective. Could not achive it. But we can see that objective do not stop increasing, but MRR for train and test datasets stopped increasing at iteraction 100:
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.001 --dim 10 --seltype random --norm --iters 500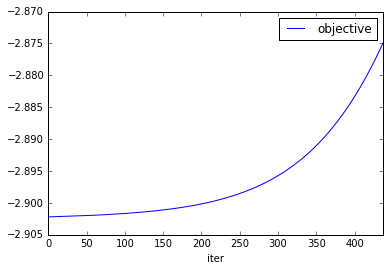
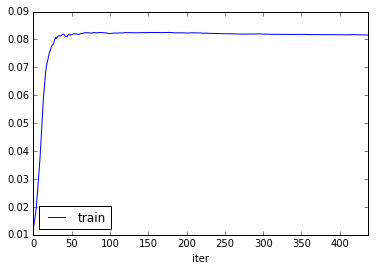
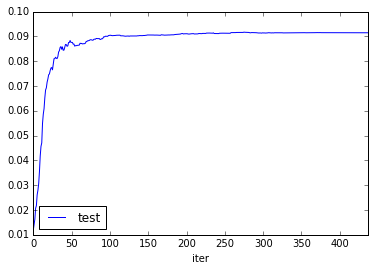
-
Tryied with a bigger step size gamma of 0.01, but stoped when achived 50 iteractions. MRR was getting slightly worst each iteraction. The last one was 0.08.
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.01 --dim 10 --seltype random --norm --iters 100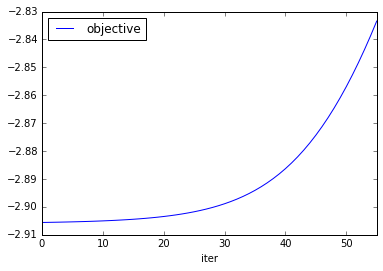
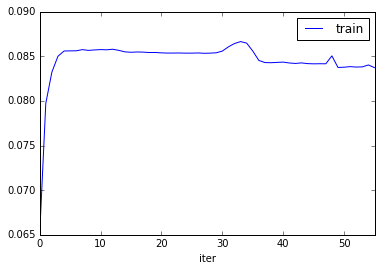
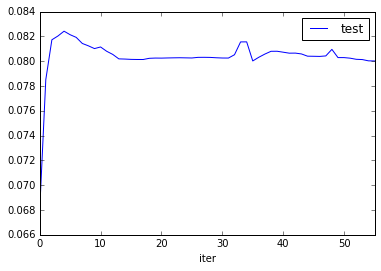
-
In this experiment I used my original experimental protocol, using only the top items for each user, randomly selecting the training and testing items from those tops. Now MRR stabilized at 0.24 from 10 iteractions and above:
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.001 --dim 10 --norm --iters 100 -
Using 20 top ratings for each user, got worst MRR (0.13), than using 5 top ratings:
python xclimf.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.001 --dim 10 --norm --iters 100 --topktrain 20 -
Comparing with ALS:
-
MRR: 0.07
$SPARK_HOME/bin/spark-submit als_spark.py --dataset data/ml-1m/ratings.dat --sep :: --iters 100 --topktrain 5 --dim 100 -
MRR: 0.04
$SPARK_HOME/bin/spark-submit als_spark.py --dataset data/ml-1m/ratings.dat --sep :: --iters 100 --topktrain 5 --dim 200 --lambda 0.01 -
MRR: 0.13
$SPARK_HOME/bin/spark-submit als_spark.py --dataset data/ml-1m/ratings.dat --sep :: --iters 100 --topktrain 5 --dim 200 --lambda 0.0001 -
MRR: 0.06
$SPARK_HOME/bin/spark-submit als_spark.py --dataset data/ml-1m/ratings.dat --sep :: --iters 100 --topktrain 5 --dim 100 --lambda 0.0001 -
MRR: 0.05
$SPARK_HOME/bin/spark-submit als_spark.py --dataset data/ml-1m/ratings.dat --sep :: --iters 100 --topktrain 20 --dim 200 --lambda 0.0001 -
MRR: 0.006
$SPARK_HOME/bin/spark-submit als_spark.py --dataset data/ml-1m/ratings.dat --sep :: --iters 100 --topktrain 5 --dim 100 --lambda 0.1
-
Running with xCLiMF Spark (https://github.com/timotta/xclimf-spark) using the best param combination we got the same MRR result of 0.23: (Normalization option not informed because xCLiMF Spark normalizes by default).
$SPARK_HOME/bin/spark-submit --driver-class-path=data/xclimf-spark.jar xclimf_spark.py --dataset data/ml-1m/ratings.dat --sep :: --lambda 0.001 --gamma 0.001 --dim 10 --iters 25
To see all options:
python xclimf.py -h
So you run like this
python xclimf.py --dataset data/ml-100k/u.data
py.test -s