Como toda grande jornada, temos aqui o início de uma, falaremos da linguagem SQL (Structured Query Language), utilizada nos principais Bancos de Dados Relacionais que temos hoje no mundo. Essa é a linguagem utilizada para criar, alterar e deletar tabelas em Bancos de Dados, também é com ela que faremos toda a manipulação dos dados dentro do nosso banco, faremos consultas, inserções, alterações, deleções e muito mais!
Para esse curso, vamos utilizar o Microsoft SQL Server Express 2019, podemos baixar o mesmo em:
Microsoft SQL Server 2019 Express
Além disso, precisamos instalar o Sistema de Gestão do nosso banco de dados, no caso do SQL Server, vamos instalar o SQL Server Management Studio (SSMS), podemos baixar o mesmo em:
Microsoft SQL Server Management Studio
Quer seguir um tutorial para instalar? Sem problema! Segue um tutorial (em inglês, depois eu faço algo em português!):
Microsoft SQL Server 2019 e Management Studio - Guias de Instalação
Qualquer coisa é só me chamar e vamos tirar todas as dúvidas!
Um Banco de Dados é uma coleção organizada de dados, estruturados ou não, normalmente armazenados em um sistema computacional. A gestáo de uma Banco de Dados é feita por um Sistema de Gestão de Bancos de Dados também conhecido como SGBD ou DBMS, em inglês.
Bancos de Dados são separados em dois tipos básicos:
Também conhecidos como bancos de dados relacionais, são bancos de dados que são formados por tabelas, que contém linhas e colunas na sua estrutura, algo como o que mostramos abaixo:
| Coluna 1 | Coluna 2 | Coluna 3 | Coluna 4 |
|---|---|---|---|
| Linha 1 | Linha 1 | Linha 1 | Linha 1 |
| Linha 2 | Linha 2 | Linha 2 | Linha 2 |
| Linha 3 | Linha 3 | Linha 3 | Linha 3 |
Cada Linha é um Registro ou Tupla, as Colunas são dos dados da Tupla. Normalmente, e por melhores práticas, os dados dentro das colunas de um registro, devem caracterizar o registro, ou seja:
| Nome | Sobrenome | Idade | Sexo |
|---|---|---|---|
| José | Silva | 17 | Masculino |
| Maria | Lins | 21 | Feminino |
| Roberto | Losada | 53 | Masculino |
Notem que em cada registro, temos dados sobre o elemento sendo descrito que o caracteriza. Agora que já entendemos a estrutura de um banco de dados SQL, temos que explicar o porque os chamamos de Relacionais, como o próprio nome diz, são bancos de dados em que suas tabelas possuem relacionamentos, ou seja, estão conectadas à outras tabelas por uma coluna, vamos a um exemplo:
Tabela Pessoa
| ID | Nome | Sobrenome | Idade | Sexo |
|---|---|---|---|---|
| 01 | José | Silva | 17 | Masculino |
| 02 | Maria | Lins | 21 | Feminino |
| 03 | Roberto | Losada | 53 | Masculino |
Tabela Endereço
| ID | Rua | Número | Complemento | Bairro | Cidade | Estado | CEP |
|---|---|---|---|---|---|---|---|
| 01 | Rua D | 01 | Apt. 01 | Vila Prudente | São Paulo | SP | 00000-000 |
| 02 | Rua A | 10 | --- | Vila Andrade | São Paulo | SP | 00000-000 |
| 03 | Rua X | 42 | Torre Sul, Apt. 53 | Centro | São Paulo | SP | 00000-000 |
Temos duas tabelas, uma com o nome das pessoas, e outra com o endereço, uma saída, não muito inteligente, seria criar um tabelão com todas as informações, porém isso nos causaria diversos problemas, dentre eles, dificuldade de manutenção, dificuldade em realizar alterações na estrutura da tabela, problemas de integridade e muito mais. Então como podemos resolver isso? Bem, podemos criar um relacionamento entre as tabelas, ou seja, usar um identificador que seja comum à ambas. Para isso, vamos considerar a seguinte relação, uma pessoa mora em um endereço, sendo assim, como cada pessoa possui um identificador único, o campo ID, ao invés de copiarmos todos os dados, simplesmente indicamos na tabela endereço qual o ID da pessoa que ali mora, tal como mostrado abaixo:
Tabela Endereço
| ID | Rua | Número | Complemento | Bairro | Cidade | Estado | CEP | ID_Pessoa |
|---|---|---|---|---|---|---|---|---|
| 01 | Rua D | 01 | Apt. 01 | Vila Prudente | São Paulo | SP | 00000-000 | 03 |
| 02 | Rua A | 10 | --- | Vila Andrade | São Paulo | SP | 00000-000 | 02 |
| 03 | Rua X | 42 | Torre Sul, Apt. 53 | Centro | São Paulo | SP | 00000-000 | 01 |
Agora a última coluna da nossa tabela de endereço contém o ID da pessoa que mora naquele endereço, ou seja, criamos um relacionamento entre as tabelas, em outras palavras, as duas compartilham um campo, que as conecta e nos permite buscar mais dados sobre um dado registro.
Em bancos de dados relacionais, a linguagem utilizada para manipular os dados é a linguagem SQL (Structured Query Language), daqui a pouco, falaremos mais sobre isso.
Os principais bancos de dados relacionais no mercado são:
- Microsoft SQL Server
- Oracle Database Server
- MySQL (Oracle)
- PostgresQL
- Apache Ignite
Outro tipo de Bancos de Dados que existe, e são largamente utilizados, são os bancos do tipo NoSQL (Not Only SQL), ao contrário dos bancos relacionais, esses bancos de dados não precisam estruturar os dados, uma vez que são altamente flexíveis quanto a sua forma de armazenagem, ou seja, eles não são estruturados. Mas o que isso quer dizer? Muito bem, em bancos relacionais, falamos de tabelas, o que obriga que todos os registros tenham a mesma estrutura ou seja, todos os campos, mesmo que vazios, mas devem possuir, tal como mostrado abaixo:
Tabela Endereço
| ID | Rua | Número | Complemento | Bairro | Cidade | Estado | CEP |
|---|---|---|---|---|---|---|---|
| 01 | Rua D | 01 | Apt. 01 | Vila Prudente | São Paulo | SP | 00000-000 |
| 02 | Rua A | 10 | --- | Vila Andrade | São Paulo | SP | 00000-000 |
| 03 | Rua X | 42 | Torre Sul, Apt. 53 | Centro | São Paulo | SP | 00000-000 |
Note que o endereço de ID 02 não possui o complemento, mesmo assim, o seu registro deve conter o campo complemento em sua estrutura, mesmo que vazio. No caso de Bancos de Dados NoSQL, isso não é necessário, a armazenagem ficaria mais ou menos assim:
{
"ID": 01,
"Rua": "Rua D",
"Número": 01,
"Complemento": "Apt. 01",
"Bairro": "Vila Prudente",
"Cidade": "São Paulo",
"Estado": "SP",
"CEP": "00000-00"
}
{
"ID": 02,
"Rua": "Rua A",
"Número": 10,
"Bairro": "Vila Andrade",
"Cidade": "São Paulo",
"Estado": "SP",
"CEP": "00000-00"
}
{
"ID": 03,
"Rua": "Rua X",
"Número": 42,
"Complemento": "Torre Sul, Apt. 53",
"Bairro": "Centro",
"Cidade": "São Paulo",
"Estado": "SP",
"CEP": "00000-00"
}O registro númeto 02, não possui o complemento, e não há problema, pois em bancos NoSQL, sua estrutura é altamente flexível. Diferente de bancos de dados realacionais, bancos de dados NoSQL, podem ser de 4 tipos:
Chave-Valor: esse é o tipo de banco de dados mais utilizado no mundo dos NoSQL, pois é extremamente simples de se utilizar e altamente confiável. Basicamente se utiliza uma chave (simples ou complexa) que nos permite buscar mais atributos do registro que queremos, um exemplo pode ser visto abaixo:
| ID Produto | Tipo | Atributo 1 | Atributo 2 | Atributo 3 |
|---|---|---|---|---|
| 1 | ID Livro | Odisséia | Homero | 1871 |
| 2 | ID Album | 6 Partitas | Bach | |
| 2 | ID Album: ID Faixa | Partita: No. 1 | ||
| 3 | ID Filme | A Criança | Drama, Comédia | Charles Chaplin |
Sendo o ID Produto a Chave de Partição, o Tipo a Chave de indexação, e os Atrbituos 1, 2 e 3 os Atributos de cada entrada.
Alguns exemplos de bancos de dados desse tipo são:
- Amazon DynamoDB
- Redis
- Aerospike
Documentos: esse tipo de banco de dados, armazena informações em documentos, que não são totalmente estruturados, como os bancos relacionais, permitindo assim que cada documento possua uma estrutura única, se necessário.
Documento 1
{
"id":"1",
"name":"John Smith",
"isActive":true,
"dob":"1964-30-08"
}Documento 2
{
"id":"2",
"fullname":"Sarah Jones",
"isActive":false,
"dob":"2002-02-18"
}Documento 3
{
"id":"3",
"fullname":
{
"first":"Adam",
"last":"Stark"
},
"isActive":true,
"dob":"2015-04-19"
}Alguns exemplos de bancos de dados deste tipo são:
- MongoDB
- CouchDB
- RavenDB
Grafos: esse tipo de banco de dados, organiza os dados como nós e as conexões (conexão entre os nós), nos nós temos os dados, que tal como os bancos de dados de Documentos, são semi-estruturados, e as conexões guardam as relações entre os nós. Muito parecido com o que vemos nas redes sociais.
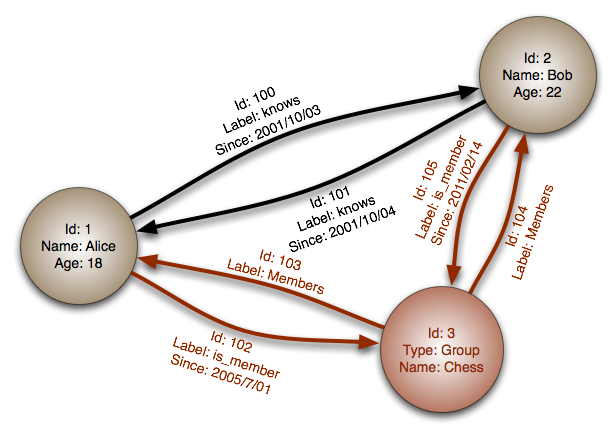
Crédito: Wikipedia - Graph Databases
Alguns exemplos de bancos de dados deste tipo são:
- Neo4j
- Apache Age
- Amazon Neptune
- Azure CosmosDB
Coluna Larga: esse tipo de banco de dados, organiza os dados em tabelas, linhas e colunas, mas não como um banco de dados relacional, cada linha tem sua própria estrutura de colunas.
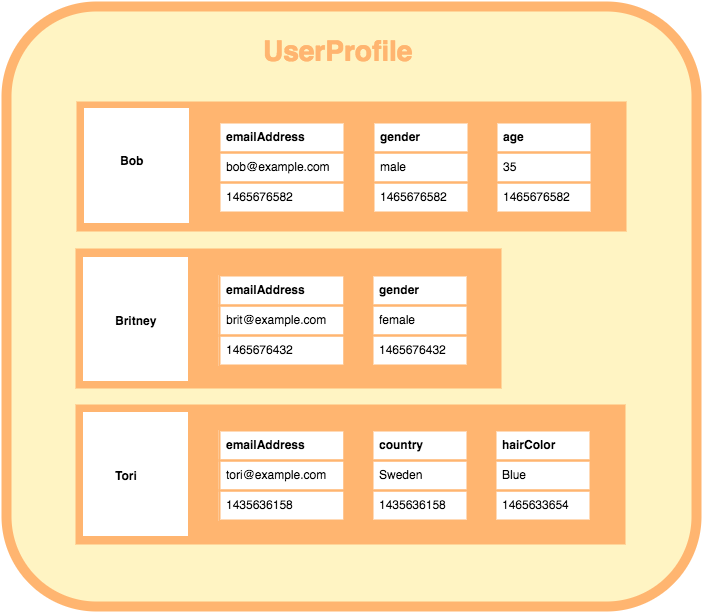
Crédito: database.guide
Alguns exemplos de bancos de dados deste tipo são:
- Google Bigtable
- Apache Cassandra
- Apache Hbase
Muito bem, agora que já vimos um pouco sobre os tipos de Bancos de Dados que existem e um pouco de como estes funcionam, podemos avançar no nosso tópico.
Muito bem, agora que já falamos dos principais tipos de bancos de dados que temos, vamos focar no que melhor representa o que estamos falando, e alguns de seus princípios básicos, ou seja, falaremos de bancos de dados relacionais.
Como falamos antes, estes bancos de dados são constituídos de tabelas, tal como mostrado abaixo: Tabela Pessoa
| ID | Nome | Sobrenome | Idade | Sexo |
|---|---|---|---|---|
| 01 | José | Silva | 17 | Masculino |
| 02 | Maria | Lins | 21 | Feminino |
| 03 | Roberto | Losada | 53 | Masculino |
Tabela Endereço
| ID | Rua | Número | Complemento | Bairro | Cidade | Estado | CEP |
|---|---|---|---|---|---|---|---|
| 01 | Rua D | 01 | Apt. 01 | Vila Prudente | São Paulo | SP | 00000-000 |
| 02 | Rua A | 10 | --- | Vila Andrade | São Paulo | SP | 00000-000 |
| 03 | Rua X | 42 | Torre Sul, Apt. 53 | Centro | São Paulo | SP | 00000-000 |
E estas tabelas podem se relacionar, tal como mostramos abaixo, que cada endereço, também possui o ID da Pessoa que ali mora.
Tabela Endereço
| ID | Rua | Número | Complemento | Bairro | Cidade | Estado | CEP | ID_Pessoa |
|---|---|---|---|---|---|---|---|---|
| 01 | Rua D | 01 | Apt. 01 | Vila Prudente | São Paulo | SP | 00000-000 | 03 |
| 02 | Rua A | 10 | --- | Vila Andrade | São Paulo | SP | 00000-000 | 02 |
| 03 | Rua X | 42 | Torre Sul, Apt. 53 | Centro | São Paulo | SP | 00000-000 | 01 |
Pois bem, o que não falamos ainda, são alguns conceitos que ocorrem dentro de tabelas de bancos de dados relacionais
Uma chave primária é um conceito básico em bancos de dados relacionais. Ela é composta por uma ou mais colunas em uma tabela que identifica exclusivamente cada registro na tabela. A chave primária é usada para garantir a integridade dos dados e garantir que não haja duplicação de registros.
Cada registro em uma tabela deve ter uma chave primária única e não nula, e os valores da chave primária devem ser diferentes para cada registro. As chaves primárias são usadas como referências para outras tabelas em um banco de dados relacionais e são usadas para garantir a integridade referencial.
Os principais tipos de chave primária são:
Chave primária simples: A chave primária simples é composta por uma única coluna em uma tabela. Por exemplo, em uma tabela de pessoas, a chave primária pode ser o cpf da pessoa, tal como mostrado abaixo:
Tabela Pessoa
| CPF | Nome | Sobrenome | Idade | Sexo |
|---|---|---|---|---|
| 111.222.333-44 | José | Silva | 17 | Masculino |
| 222.333.444-55 | Maria | Lins | 21 | Feminino |
| 333.444.555-66 | Roberto | Losada | 53 | Masculino |
CREATE TABLE pessoa
(
cpf INT,
nome VARCHAR(32),
sobrenome VARCHAR(32),
idade INT,
sexo VARCHAR(16),
PRIMARY KEY (cpf)
);No caso acima, temos uma chave primária simples, formada pelo CPF, pois este identifica unicamente cada Pessoa de nossa tabela, é IMPORTANTE ressaltar que chaves primárias não pode conter réplicas ou duplicatas no banco de dados, ou seja, estas são únicas, pois devem assim garantir a unicidade e integridade dos dados.
Chave primária composta: A chave primária composta é composta por duas ou mais colunas em uma tabela. Por exemplo, em uma tabela de pedidos, a chave primária pode ser composta pela combinação do número de pedido e do número de linha.
Tabela Pedido
| Numero_Pedido | Linha_Pedido | Numero_Item | Descricao_Item | Quantidade |
|---|---|---|---|---|
| 00001 | 01 | 12345 | Parafuso Aço 16x3 | 3 |
| 00001 | 02 | 23456 | Rosca Aço 5x3 | 3 |
| 00001 | 03 | 34567 | Prego Anodizado 15x2 | 100 |
| 00002 | 01 | 12345 | Parafuso Aço 16x3 | 45 |
| 00002 | 02 | 34567 | Prego Anodizado 15x2 | 1000 |
CREATE TABLE pedido
(
numero_pedido INT,
linha_pedido INT,
numero_item INT,
descricao_item VARCHAR(256),
quantidade_item INT,
PRIMARY KEY (numero_pedido, linha_pedido)
);Em chaves compostas a unicidade é encontrada, ao combinarmos os dois campos, o que garante que sempre tenhamos um número único identificando o registro.
Chave primária artificial: A chave primária artificial é uma criada pelo banco de dados em vez de usar uma chave natural. A chave primária artificial é útil quando não há uma coluna adequada na tabela para atuar como chave primária, ou quando a chave natural é muito grande ou complexa. Por exemplo, em uma tabela de clientes, o banco de dados pode criar uma chave primária artificial simplesmente atribuindo um número exclusivo a cada registro.
Tabela Clientes
| Cliente_PK | Numero_Cliente | Nome_Cliente | Agencia_Cliente | Conta_Cliente |
|---|---|---|---|---|
| 001 | 9876 | Cliente 1 | Agência 1 | 12345 |
| 002 | 9877 | Cliente 2 | Agência 1 | 12346 |
| 003 | 9878 | Cliente 3 | Agência 2 | 12345 |
| 004 | 9879 | Cliente 4 | Agência 2 | 12346 |
| 005 | 9880 | Cliente 5 | Agência 3 | 12347 |
CREATE TABLE clientes
(
cliente_pk INT AUTO INCREMENT,
numero_cliente INT,
nome_cliente VARCHAR(64),
agencia_cliente VARCHAR(64),
conta_cliente INT,
PRIMARY KEY (cliente_pk)
)A chave primária aqui é criada para garantir a unicidade dos registros, e esta não é um campo do cliente, e sim um campo criado, existem várias formas de se criar essa chave, podendo a mesma ser sequêncial, ou um UUID (Universally Unique Identifier).
Em SQL, uma chave estrangeira é um campo ou conjunto de campos em uma tabela que se refere a uma chave primária em outra tabela. Ela é usada para estabelecer um relacionamento entre duas tabelas, permitindo que os dados de uma tabela sejam relacionados com os dados de outra tabela. A chave estrangeira ajuda a manter a integridade referencial entre as tabelas, garantindo que os dados relacionados estejam sempre sincronizados.
Aqui está um exemplo de tabelas com relacionamento usando chave estrangeira, nas tabelas que já criamos acima:
Tabela Clientes
| Cliente_PK | Numero_Cliente | Nome_Cliente | Agencia_Cliente | Conta_Cliente |
|---|---|---|---|---|
| 001 | 9876 | Cliente 1 | Agência 1 | 12345 |
| 002 | 9877 | Cliente 2 | Agência 1 | 12346 |
| 003 | 9878 | Cliente 3 | Agência 2 | 12345 |
| 004 | 9879 | Cliente 4 | Agência 2 | 12346 |
| 005 | 9880 | Cliente 5 | Agência 3 | 12347 |
CREATE TABLE clientes
(
cliente_pk INT AUTO INCREMENT,
numero_cliente INT,
nome_cliente VARCHAR(64),
agencia_cliente VARCHAR(64),
conta_cliente INT,
PRIMARY KEY (cliente_pk)
)Tabela Pedido
| ID_Cliente | Numero_Pedido | Linha_Pedido | Numero_Item | Descricao_Item | Quantidade |
|---|---|---|---|---|---|
| 001 | 00001 | 01 | 12345 | Parafuso Aço 16x3 | 3 |
| 001 | 00001 | 02 | 23456 | Rosca Aço 5x3 | 3 |
| 001 | 00001 | 03 | 34567 | Prego Anodizado 15x2 | 100 |
| 003 | 00002 | 01 | 12345 | Parafuso Aço 16x3 | 45 |
| 003 | 00002 | 02 | 34567 | Prego Anodizado 15x2 | 1000 |
CREATE TABLE pedido
(
id_cliente INT,
numero_pedido INT,
linha_pedido INT,
numero_item INT,
descricao_item VARCHAR(256),
quantidade INT,
PRIMARY KEY (numero_pedido, linha_pedido),
FOREIGN KEY (id_cliente) REFERENCES clientes(cliente_pk)
)No nosso caso acima, o campo Cliente_PK, da tabela Clientes, que é a chave primária dessa tabela, é utilizado como chave estrangeira na tabela Pedido, no campo ID_Cliente.
Podemos estruturar a linguagem SQL em 5 subconjuntos de Linguagem, são estes:
- DQL (Data Query Language): define o comando de consulta de dados, a saber, o comando SELECT, que como o próprio nome diz, seleciona os dados nas fontes que queremos, alguns exemplos são:
- DML (Data Manipulation Language): define os comandos de manipulação do banco de dados (INSERT, UPDATE e DELETE)
- DDL (Data Definition Language): define os comandos para manipulação de tabelas, views, índices e atualização (CREATE, ALTER e DROP)
- DCL (Data Control Language): define os comandos de controle de acesso ao banco de dados (GRANT e REVOKE)
- DTL (Data Transaction Language): define os comandos de gestão das transações de bancos de dados (BEGIN, COMMIT e ROLLBACK)
Cada dado que armazenamos possui um tipo, pode ser um número inteiro, um número decimal, uma palavra, uma data ou até mesmo um arquivo, entre outros.
Tipos Inteiros:
- INT: armazena números inteiros na faixa de -2.147.483.648 a 2.147.483.647.
- BIGINT: armazena números inteiros maiores na faixa de -9.223.372.036.854.775.808 a 9.223.372.036.854.775.807.
- SMALLINT: armazena números inteiros menores na faixa de -32.768 a 32.767.
- TINYINT: armazena números inteiros muito pequenos na faixa de -128 a 127.
Tipos Decimais ou Numéricos:
- DECIMAL ou NUMERIC: armazena números com ponto fixo com uma precisão e escala especificadas.
- FLOAT: armazena números de ponto flutuante com uma precisão especificada.
- REAL: armazena números de ponto flutuante com uma precisão de 7 dígitos.
Tipos de Strings de Caracteres:
- CHAR: armazena strings de caracteres com comprimento fixo.
- VARCHAR: armazena strings de caracteres com comprimento variável com um comprimento máximo.
- TEXT: armazena strings de caracteres grandes com um comprimento máximo de 2^31-1 caracteres.
Tipos de Datas e Horas:
- DATE: armazena datas no formato AAAA-MM-DD.
- TIME: armazena horários no formato HH:MM:SS.
- DATETIME: armazena datas e horários no formato AAAA-MM-DD HH:MM:SS.
- TIMESTAMP: armazena datas e horários no formato AAAA-MM-DD HH:MM:SS com microssegundos.
O comando SELECT é utilizado sempre que queremos BUSCAR informações no nosso banco de dados, podendo essa informação estar em uma ou mais tabelas, com uma ou mais condições.
1. Buscar os dados de todas as colunas de uma tabela:
SELECT * FROM tabela; 2. Buscar todos os dados de apenas uma coluna:
SELECT nome FROM tabela;3. Buscar todos os dados de mais de uma coluna:
SELECT nome, sobrenome, endereço FROM tabela;4. Buscar os dados de mais uma coluna sendo que uma das colunas venha ordenada em ascendente
SELECT matricula, nome, sobrenome, endereço FROM tabela ORDER BY matricula ASC;5. Buscar os dados de mais uma coluna sendo que uma das colunas venha ordenada em descendente
SELECT matricula, nome, sobrenome, endereço FROM tabela ORDER BY matricula DESC;6. Buscar os dados de uma coluna, porém garantindo que traga apenas valores únicos
SELECT DISTINCT(endereço) FROM tabela;7. Buscar os dados de várias colunas mas que sejam maiores ou iguais à um determinado valor
SELECT matricula, nome, sobrenome FROM tabela WHERE matricula >= 1000;8. Buscar os dados de várias colunas mas que sejam menores ou iguais à um determinado valor
SELECT matricula, nome, sobrenome FROM tabela WHERE matricula <= 1000;9. Buscar os dados de várias colunas mas que sejam exatamente iguais à um determinado valor
SELECT matricula, nome, sobrenome FROM tabela WHERE matricula = 1000;10. Buscar os dados de várias colunas mas que sejam seu valor esteja entre dois valores
SELECT matricula, nome, sobrenome FROM tabela WHERE matricula BETWEEN 500 AND 1000;11. Buscar os dados de várias colunas, mas que possuam um valor texto específico
SELECT matricula, nome, sobrenome FROM tabela WHERE nome = 'Igor';12. Buscar os dados de várias colunas, mas que contenham valores texto que estão em uma lista
SELECT matricula, nome, sobrenome FROM tabela WHERE nome IN ('Igor','Eric');13. Buscar os dados de várias colunas, mas que contenham valores que comecem com um caractere
SELECT matricula, nome, sobrenome FROM tabela WHERE nome LIKE 'I%';14. Buscar os dados de várias colunas, mas que contenham valores que não comecem com um caractere
SELECT matricula, nome, sobrenome FROM tabela WHERE nome NOT LIKE 'I%';15. Buscar os dados de várias colunas, mas que contenham valores que não comecem com um caractere
SELECT matricula, nome, sobrenome FROM tabela WHERE nome NOT LIKE 'I%';16. Buscar os dados de várias colunas, porém filtrando por mais de uma coluna
SELECT matricula, nome, sobrenome FROM tabela WHERE nome LIKE 'I%' AND matricula >= 1000;17. Buscar os dados de várias colunas, porém filtrando apenas aqueles que possuem o campo desejado vazio
SELECT matricula, nome, sobrenome FROM tabela WHERE sobrenome IS NULL;18. Buscar os dados de várias colunas, porém filtrando apenas aqueles que possuem o campo desejado não vazio
SELECT matricula, nome, sobrenome FROM tabela WHERE sobrenome IS NOT NULL;19. Buscar os dados de várias colunas, porém filtrando apenas aqueles que possuem o campo desejado não vazio
SELECT matricula, nome, sobrenome FROM tabela WHERE sobrenome IS NOT NULL;20. Somar todos os valores de uma coluna
SELECT SUM(salario) FROM tabela;21. Realizar a média de todos os valores de uma coluna
SELECT AVG(salario) FROM tabela;22. Achar o maior de todos os valores de uma coluna
SELECT MAX(salario) FROM tabela;23. Achar o menor de todos os valores de uma coluna
SELECT MIN(salario) FROM tabela;24. Contar o total de Matrículas que as pessoas tenham o mesmo primeiro nome
SELECT nome, COUNT(matricula) FROM tabela GROUP BY nome;25. Contar o total de Matrículas que as pessoas tenham o mesmo primeiro nome que seja Igor ou Eric
SELECT nome, COUNT(matricula) FROM tabela WHERE nome IN ('Igor','Eric') GROUP BY nome;26. Contar o total de Matrículas que as pessoas tenham o mesmo primeiro nome e que seja um total maior que 100
SELECT nome, COUNT(matricula) FROM tabela GROUP BY nome HAVING COUNT(matricula) > 100;O comando INSERT é utilizado para inserir dados nas tabelas dos bancos de dados. 1. Inserindo um único registro em uma tabela
INSERT INTO tabela (matricula, nome, sobrenome, endereco, numero, complemento, cep)
VALUES (1234, 'José', 'Ferez', 'Rua das Acácias', 22, '114A', '12345-001');2. Inserindo múltiplos registros em uma tabela
INSERT INTO tabela (matricula, nome, sobrenome, endereco, numero, complemento, cep);
VALUES (1234, 'José', 'Ferez', 'Rua das Acácias', 22, '114A', '12345-001'),
(1235, 'Joana', 'Ferez', 'Rua das Acácias', 22, '114A', '12345-001'),
(1236, 'Xavier', 'Wadinton', 'Rua Terra Azul', 135, '15', '23456-007');O comando UPDATE é utilizado para alterar os valores dentro de uma tabela. Podendo ou não (ATENÇÃO!) ter uma condição para tal.
1. Atualizando um único registro em uma tabela
UPDATE tabela SET salario = 60000 WHERE matricula = 1234;2. Atualizando vários registros em uma tabela
UPDATE tabela SET salario = 100000 WHERE departamento = 'TI';3. Atualizando um registro com uma valor vazio (NULL)
UPDATE tabela SET salario = NULL WHERE matricula = 1234;BÔNUS O famoso update da Sexta-Feira (o dia de maldade)
UPDATE tabela SET salario = NULL;O comando DELETE, apaga os conteúdo de uma tabela, podendo ou não (ATENÇÃO!) ter uma condição.
1. Apagando um registro de uma tabela
DELETE FROM tabela WHERE matricula = 1234;2. Apagando vários registros de uma tabela com base em uma condição
DELETE FROM tabela WHERE matricula >= 1234 AND matricula <= 2345;3. Apagando todos os registros de uma tabela (Irmão do Update Sexta Feira)
DELETE FROM tabela;O comando CREATE, como o próprio nome diz, é utilizado para se criar estruturas no nosso banco de dados, podendo ser uma banco de dados completo, uma tabela, um índice ou muito mais.
1. Criando um Banco de Dados
CREATE DATABASE empresa;2. Criando uma tabela
CREATE TABLE funcionarios (
id INT PRIMARY KEY,
nome VARCHAR(50),
departmento VARCHAR(50),
salario DECIMAL(10,2)
);3. Criando um índice
CREATE INDEX idx_empregado_departmento ON funcionarios (departmento);4. Criando uma View
CREATE VIEW funcionario_salario AS
SELECT nome, salario
FROM funcionarios;EXTRA: Além do que citamos acima, ainda podemos criar TRIGGERS, PROCEDURES e FUNCTIONS, mas isso é assunto para outro dia!
O comando ALTER, permite que sejam alteradas características da base de dados, desde as configurações do banco de dados até uma coluna ou um índice.
1. Alterar configurações de um Banco de Dados Existente
ALTER DATABASE empresa
SET DEFAULT_CHARACTER_SET = 'utf8';2. Alterar a estrutura de uma tabela existente adicionando, modificando e excluindo colunas
ALTER TABLE funcionarios
ADD email VARCHAR(50);
ALTER TABLE funcionarios
MODIFY COLUMN salario DECIMAL(12,2);
ALTER TABLE funcionarios
DROP COLUMN departmento;3. Alterar o índice de um banco de dados
ALTER INDEX idx_funcionario_salarioo
RENAME TO idx_salario;
ALTER INDEX idx_salario
ADD COLUMN departmento;4. Alterar uma view no banco de dados
ALTER VIEW funcionario_salario
AS
SELECT nome, salario, departmento
FROM funcionarios;EXTRA: Além do que citamos acima, ainda podemos alterar TRIGGERS, PROCEDURES e FUNCTIONS, mas isso é assunto para outro dia!
O comando DROP, permite que excluamos estruturas do banco de dados, desde um índice, uma tabela até um banco de dados inteiro.
1. Exclui uma tabela existente
DROP TABLE funcionarios;2. Exclui um índice existente
DROP INDEX funcionarios;3. Exclui um banco de dados existente
DROP INDEX empresa;4. Exclui uma view existente
DROP VIEW funcionario_salario;EXTRA: Além do que citamos acima, ainda podemos excluir TRIGGERS, PROCEDURES e FUNCTIONS, mas isso é assunto para outro dia!
Um ALIAS é um nome alternativo que é atribuído a uma tabela, coluna, ou expressão para simplificar o seu uso em uma consulta.
1. Alias de uma tabela
SELECT func.id, func.nome, func.sobrenome
FROM funcionarios AS func;2. Alias de uma coluna
SELECT func.id AS "ID Funcionario", func.nome AS "Nome Funcionario", func.sobrenome AS "Sobrenome Funcionario"
FROM funcionarios AS func;JOIN é uma operação que combina dados de duas ou mais tabelas em uma única consulta, com base em uma relação comum entre elas. O JOIN é usado para recuperar informações que estão distribuídas em várias tabelas relacionadas entre si, permitindo que essas tabelas sejam combinadas em uma única consulta.
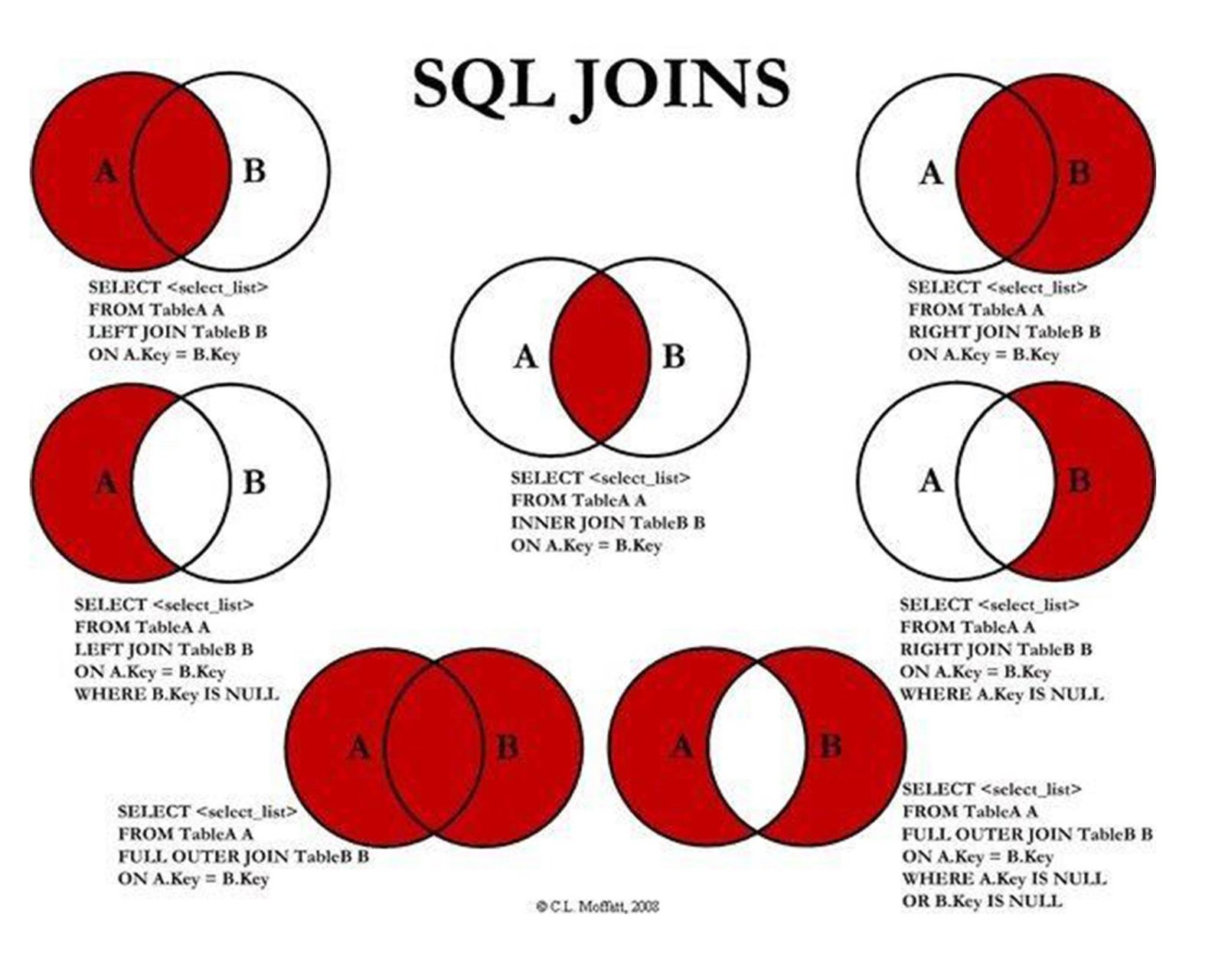
Os tipos de JOIN, são os seguintes:
1. INNER JOIN: retorna apenas os registros que têm correspondência em ambas as tabelas envolvidas na operação JOIN. Essa é a operação JOIN padrão em SQL.
SELECT pedidos.id_pedidos, clientes.nome
FROM pedidos
INNER JOIN clientes
ON pedidos.id_cliente = clientes.id_cliente;2. LEFT JOIN: retorna todos os registros da tabela da esquerda e os registros correspondentes da tabela da direita. Se não houver correspondência, o resultado da tabela da direita será NULL.
SELECT clientes.nome, pedidos.id_pedidos
FROM clientes
LEFT JOIN pedidos
ON clientes.id_clientes = pedidos.id_clientes;3. RIGHT JOIN: retorna todos os registros da tabela da direita e os registros correspondentes da tabela da esquerda. Se não houver correspondência, o resultado da tabela da esquerda será NULL.
SELECT clientes.nome, pedidos.id_pedidos
FROM clientes
RIGHT JOIN pedidos
ON clientes.id_clientes = pedidos.id_clientes;4. FULL OUTER JOIN: combina todos os registros de ambas as tabelas envolvidas na operação JOIN, incluindo aqueles que não têm correspondência em uma ou em ambas as tabelas.
SELECT clientes.nome, pedidos.id_pedidos
FROM clientes
FULL OUTER JOIN pedidos
ON clientes.id_clientes = pedidos.id_clientes;